Just over two years ago, I landed the first commit in a fresh Github repo and started the Breadboard project. The innocuous “Here is a graph” title of that commit already pointed to where I wanted to go – a graph-based system for composing what I later named “AI patterns” and even later, “Recipes for Thought”.
When Opal launched on July 24, folks familiar with Breadboard must have done a double-take: the familiar user interface of Breadboard was strongly hinting at Opal’s open source heritage.
Yup. Opal is built with Breadboard. It follows a common pattern in open source software, where the project is open source, but the product that’s built on it is not.
I learned this pattern when I was working on the Chrome team at Google – now a long time ago. Though free, Chrome was (and still is) commercial software, with all the care and diligence that goes into shipping it. At the same time, most of that browser’s code was (and still is) open source: not only could you see it all, you could (and many did) contribute to it, just like in a typical open source project. Even though I worked at Google, all of my work was out in the open. I worked on the Chromium project – and that project was the backbone of the product called “Chrome”.
This interesting project/product relationship is somewhat unique to the open source world. Most non-open source projects don’t have to draw that line, and it’s mostly blurred or entirely invisible. There, the project is roughly equivalent to the product.
In an open source project, the line is much more crisp, and becomes significant. The project becomes its own thing, with a community around it, and even other ways in which the source code of the project is used. Many modern browsers trace their heritage back to Chromium. Node.Js was built on V8, the JavaScript engine that Chromium introduced. The ever-popular VS Code is built on Electron, which is a fork of Chromium. A healthy open source project is a product in itself, with its own audience, its own niche, and its own set of product market fit challenges. A healthy open source project has a whole ecosystem around it.
Breadboard and Opal follow the same pattern. Breadboard is the open source project where all of Opal’s code lives. Opal is the product that we ship at Labs. Just like Chrome, we take the Breadboard code, apply a bit of configuration, and then serve it from opal.withgoogle.com.
This setup allows us to expand the potential impact of Opal. I started the Breadboard project because I believed (and still do!) that more people having access to tools to compose LLMs into something interesting would allow us to better understand the full potential of the current generation of what we call “artificial intelligence” and move beyond the hype – beyond anxious anticipation of what LLM – and be more empowered to make sense of them.
I’d like to present to you a distinction: two different approaches I take when using large language models (LLMs). I’ll call these two approaches “chat” and “recipe”.
In the first approach, I treat my interaction with Gemini, ChatGPT, et al. as a conversation: I type something, the LLM replies, I type again, etc. Very familiar, right? It’s how we talk to other humans. This is the “chat” approach and it seems to be quite dominant in the modern AI landscape, so I am not going to spend much time studying it.
Now, let’s step out of the familiar and change the perspective a little bit. Instead of seeing it as an unstructured back-and-forth, let’s treat the turns of the conversation as going through steps in a recipe. Each step contains a prompt from me and a generated reply from the LLM.
The shift is subtle, but it’s there. I am no longer chatting. I am guiding the LLM through the steps of a recipe for thought. “First think this way, then think that way, and now think like this”. With each step, the LLM’s replies get closer to the final product of the recipe.
If you observe me use this approach with an LLM, you’ll notice a difference right away in how I treat the conversation turns.
Suppose I type: “Write me a story” – and an LLM writes a story about … the Last Custodians of Dreams. It’s nice, but as I read it, I am realizing that I actually want a story about dolphins.
When using the “chat” approach, I simply ask the LLM to fix the problem in the next conversation turn. “No, I want a story about dolphins”.
With the “recipe” approach, I click the little “Edit” icon next to my first turn’s prompt and edit it to refine it: “Write me a story about dolphins”.
Okay, the response is much closer, but now I see how this story is too short. Hmm.. how do I make it stretch the response a bit? Perhaps I need to first let the LLM consider the full story ark – and then fill in the details?
So I edit the first turn prompt again: “Write an outline of a story about dolphins. Anthropomorphize dolphins to tell a story about being alone, but not lonely.” Alright! This outline feels much closer to the story I want to see.
All this time, I was still in the first conversation turn! Now, I am ready to move to the next turn: presumably, asking an LLM to start adding details to the outline.
The end result might only look like a very brief conversation, but the outcome is typically much better: the continuous refinement of the prompt at each turn and carefully shaping the structure of the recipe results in the LLM output that I actually want.
The reason for that is the nature of the process of finding the right recipe. When building one, we try to better understand how an LLM thinks – and more importantly, how we think about the problem. I find the recipe approach very similar to mentoring: in the process of teaching it to follow my recipe, I learn just as much about my own cognitive processes. How do I typically think about writing a story? What are the steps that I myself take to ensure that the story is novel, coherent, and interesting?
This process of thinking about our own thinking is called metacognition. When using the “recipe” approach, we engage in metacognition for both the LLM and ourselves. Using our prompts as probes, we explore what an LLM is capable of and what prompts yield better results. We also are challenged to uncover our own tacit knowledge and turn it into a sequence (or a graph!) of prompts that an LLM can easily follow.
Metacognition is easier for some and more difficult for others. I know many folks who are experts at their stuff, but suffer from the “Centipede’s Dilemma”, unable to explain their own thought process – their expertise is entirely submerged in the subconscious.
However, if metacognition is something that we’re used to, we can now, through the “recipe” approach, transfer our thought processes onto recipes. We can let LLMs do our thinking for us, because – plot twist! – we can make these recipes repeatable.
Observe: once I have a complete recipe for writing a story about dolphins, all I need is a way to substitute the word “dolphin” in the first prompt for another creature – and to re-run all the steps in the recipe! Now I can generate great stories about monkeys, doves, cats, and turtles. By parametrizing our recipes, we can make them generic and applicable to a variety of inputs.
Stories about animals are great, but let’s step back and engage our meta-metacognition. Hoo-boy, we must go deeper. What kind of metacognition are we seeing here? If we were to describe the pattern generally, what’s being described above is a process of transferring cognitive know-how – some expertise of thinking about a problem – into a repeatable recipe.
We all have cognitive know-how, even if we don’t realize it. More importantly, we all have potential for drawing value from this know-how beyond our individual use.
There’s a saying that goes “if you want something done right, do it yourself”. The thinking recipes allow us to amend the last part to “make a repeatable thinking recipe for it, and let the LLM do it”.
An expert in organizational strategy will undoubtedly have a wealth of cognitive know-how on the topic, from listening and interviewing, to running the sessions to generate insights, to coalescing disparate ideas into crystal clear definitions of the problem, and so on. Whenever this expert engages with a client, they have a playbook that they run, and this playbook is well-scripted in their mind.
I once was so impressed with a training session on team communication that I just had to reach out to the speaker and ask them for the script. If I had this script, I ought to have a way to run these sessions for all of my team. I was quite shaken to learn when the speaker revealed that what she had was more like a hundred fragments of the session puzzle that she puts together more or less on the fly, using the audience as a guide to which fragment to pick next. What to me looked like a simple linear flow was actually a meandering journey through a giant lattice of cognitive know-how.
In both cases, the cognitive know-how is trapped inside of the experts’ heads. If they wish to scale, go bigger or wider, they immediately run into the limitations of having just one person traversing their particular cognitive know-how lattices.
However, if they could transfer their lattices into repeatable reasoning recipes, the horizons expand. At the very least, the LLM armed with such a recipe, can produce a decent first draft of the work – or ten! When I am applying repeatable reasoning recipes, my job shifts from following my own know-how to reviewing and selecting the work, produced by a small army of artificial apprentices.
Repeatable thinking recipes allow us to bust through the ceiling of generic thinking that the current LLMs seem to be stuck under – not by making them omniscient and somehow intuiting exactly what we’re asking for, but by investing a bit of time into turning our own cognitive know-how into recipes to help us think at scale.
This is not just a matter of scaling. With scale come new possibilities. When the overall cost of running through a recipe goes way down, I can start iterating on the recipe itself, improving it, adding new ingredients, and playing with new ideas – ideas that I wouldn’t have had the opportunity to explore without having my artificial apprentices.
I facilitated a workshop on systems thinking recently (or “lensical thinking” as I’ve come to call it). The purpose of the lensical thinking workshop is to provide a coherent set of tools for approaching problems of particularly unsolvable kind, using the concept of lenses as the key organizing concept.
One of the participants became quite fond of the polarity lens, realizing how broadly applicable it is, from the larger organizational challenges (like “centralized vs. decentralized”), to something as in-the-moment as hidden tension in a conversation.
The participant even pointed out that the use of lenses, at its core, has a polarity-like quality: a wide diversity of lenses brings more nuance to the picture and as such, makes the picture less simple and crisp. The tension between the desire for clarity and the desire to see the fuller picture are in tension, causing us – if we’re not careful – to swing wildly between the two extremes.
That one resonated with me, because it’s a very common problem that every leader faces: in a vastly complex space of mostly unsolvable problems, how do they speak with clarity and intention while still leaving room for nuance and convey who fuzzy everything actually is?
The deeper insight here is that we are surrounded by polarities. Behind every bad decision, there is undoubtedly a pair of what seems like two equally bad conflicting options and the agony of having to commit to one – often knowing full well that some time from now, we’ll have to swing all the way to the other side. In that moment, the polarities rule us, both individually and collectively.
In a separate conversation with a dear friend of mine, we arrived at a point of clarity when we both saw how a problem we’ve been looking at was a gnarly polarity. We saw how, over time, the only seemingly available options had this quality of “either do <clearly unsatisfying thing> or do <another clearly unsatisfying thing>”, repeating over and over.
When that happened, we both felt a bit of a despondence setting it. This has been going on for a long time. What is the way out of this swing of a pendulum? Is there even one?
This question was surprisingly helpful: “What’s the third option?” When caught in the grip of the polarity, it feels counterintuitive to slow down and look around for something other than the usual. However, given that the other choices leave us animated by the pendulum, the least we can do is to invest into observing what is happening to us.
The third option is definitely that of deciding to do better this time, now that we’ve seen how we are subject to polarity. We may claim to have a more active role, to elevate the polarity into something productive, and many consulting hours are spent heaving that weight. Unfortunately, the pendulum cares very little about that. And inevitably, we find ourselves back in its grip.
The third option is rarely that of nihilism, of deciding that the world around us is inherently bad and we are better off uncontaminated by it. The WarGames ending was beautiful, but in a polarity, it’s an option that is chosen when guided by naivete – for nihilism and naivete are close cousins.
The third option is rarely that of avoidance – even if it’s the avoidance through drastic action, like proclaiming that we’re moving to an island/starting a new business/adventure, or joining a group of like-minded, clear-sighted individuals that suspiciously smells like a cult. When we choose this path, we mustn’t be surprised how the same old chorus cuts into our apparently new song.
The presence of a polarity is a sign that our thinking is too constrained, flattened either by the burden of the allostatic load or simply the absence of experience with higher dimensional spaces. The search for the “third option” is an attempt to break out of a two-dimensional picture – into the third dimension, to see the limits of the movements along the X and Y axis and look for ways to fold our two-dimensional space into the axis Z.
Put differently, polarities are a sign that our mental modals are due for reexamination. Polarities, especially particularly vicious ones, are a blinking light on our dashboard of vertical development. This means that the third option will not be obvious and immediately seen. “Sitting with it” is a very common refrain of third-option seekers. The axis Z is hard to comprehend with a two-dimensional brain, and some serious stretching of the mind will be necessary to even catch the first glimpses of it.
Most significantly, that first glimpse or even a full realization doesn’t not necessarily bring instant victory. Orthogonality is a weird trick. Opening up a new dimension does not obsolete the previous ones – it just creates more space. Those hoping for a neat solution will be disappointed.
Instead of “solving” a polarity, we might find a whole different perspective, which may not change the situation in a dramatic way – at least not at first. We might find that we are less attached to the effects of a pendulum. We might find that we no longer suffer at the extremes, and have a tiny bit more room to move, rather than feeling helpless. We might find that the pendulum swings no longer seem as existential. And little by little, its impact on us will feel less and less intense.
I did this fun little experiment recently. I took my two last posts (Thinking to Write and The Bootstrapping Phase) and asked an LLM to turn them into lyrics. Then, after massaging the lyrics a bit, to better fit with the message I wanted to come across, I played with Suno for a bit to transform them into short, 2-minute songs – a sort of vignettes for my long-form writing. Here they are:
Catchy, content-ful, and in total, maybe 20 minutes to make. And, it was so much fun! I got to think about what’s important, how to express somewhat dry writing as emotionally interesting. I got to consider what music style would resonate with what I am trying to convey in the original content.
This got me thinking. What I was doing in those few minutes was transforming the medium of the message. With generative AI, the cost of medium transformation seems to be going down dramatically.
I know how to make music. I know how to write lyrics. But it would have taken me hours of uninterrupted time (which would likely translate into months of elapsed time) to actually produce something like this. Such investment makes medium transformation all but prohibitive. It’s just too much effort.
However, with the help of a couple of LLMs, I was able to walk over this threshold like there’s nothing to it. I had fun, and – most importantly – I had total agency in the course of the transformation. I had the opportunity to tweak the lyrics. I played around with music styles and rejected a bunch of things I didn’t like. It was all happening in one-minute intervals, in rapid iteration.
This rapid iteration was more reminiscent of jamming with a creative partner than working with a machine. Gemini gave me a bunch of alternatives (some better than others), and Suno was eager to mix bluegrass with glitch, no matter how awful the results. At one moment I paused and realized: wow, this feels closer to the ideal creative collaboration than I’ve ever noticed before.
What’s more importantly, the new ease of medium transformation opens up all kinds of new possibilities. If we presume – and that’s a big one – for a moment that the cost of medium transformation will indeed go down for all of us, we now can flexibly adjust the medium according to the circumstances of the audience.
The message does not have to be locked in a long-form post or an academic tome, waiting for someone to summarize it in an easily consumable format. We can turn it into a catchy tune, or a podcast. It could be a video. It could be something we don’t yet have, like a “zoomable” radio station where I listen to a stream of short-form snippets of ideas, and can “zoom in” to the ones I am most interested in, pausing the stream to have a conversation with the avatar of the author of the book, or have an avatar of someone I respect react to it. I could then “zoom out” again and resume the flow of short-form snippets.
Once flexible, the medium of the message can adapt and meet me where I am currently.
The transformation behind this flexibility will often be lossy. Just like the tweets pixelate the nuance of the human soul, turning a book into a two-verse ditty will flatten its depth. My intuition is that this lossiness and the transformation itself will usher in a whole new era of UX explorations, where we struggle to find that new shared way of interacting with the infinitely flexible, malleable canvas of the medium. Yup, this is going to get weird.
This one is also a bit on the more technical side. It’s also reflective of where most of my thinking is these days. If you enjoy geeking out on syntaxes and grammars of opinionated Javascript APIs, this will be a fun adventure – and an invitation.
In this essay, I’ll describe the general approach I took in designing the Breadboard library API and the reasoning behind it. All of this is still in flux, just barely meeting the contact with reality.
One of key things I wanted to accomplish with this project is the ability to express graphs in code. To make this work, I really wanted the syntax to feel light and easy, and take as few characters as possible, while still being easy to grasp. I also wanted for the API to feel playful and not too stuffy.
There are four key beats to the overall story of working with the API:
1️⃣ Creating a board and adding kits to it 2️⃣ Placing nodes on the board 3️⃣ Wiring nodes 4️⃣ Running and debugging the board.
Throughout the development cycle, makers will likely spend most of their time in steps 2️⃣ and 3️⃣, and then lean on step 4️⃣ to make the board act according to their intention. To get there with minimal suffering, it seemed important to ensure that placing nodes and wiring them results in code that is still readable and understandable when running the board and debugging it.
This turned out to be a formidable challenge. Unlike trees, directed graphs – and particularly directed graphs with cycles – aren’t as easy for us humans to comprehend. This appears to be particularly true when graphs are described in the sequential medium of code.
I myself ended up quickly reaching for a way to visualize the boards I was writing. I suspect that most API consumers will want that, too – at least at the beginning. As I started developing more knack for writing graphs in code, I became less reliant on visualizations.
To represent graphs visually, I chose Mermaid, a diagramming and charting library. The choice was easy, because it’s a library that is built into Github Markdown, enabling easy documentation of graphs. I am sure there are better ways to represent graphs visually, but I followed my own “one miracle at a time” principle and went with a tool that’s already widely available.
🎛️ Placing nodes on the board
The syntax for placing nodes of the board is largely inspired by D3: the act of placement is a function call. As an example, every Board instance has a node called `input`. Placing the `input` node on the board is a matter of calling `input()` function on that instance:
import{Board}from “@google-labs/breadboard”;// create new Board instanceconstboard=newBoard();// place a node of type `input` on the board.board.input();
After this call, the board contains an input node.
You can get a reference to it:
constinput=board.input();
And then use that reference elsewhere in your code. You can place multiple inputs on the board:
Similarly, when adding a new kit to the board, each kit instance has a set of functions that can be called to place nodes of various types on the board to which the kit was added:
import{Starter}from “@google-labs/llm-starter”;// Add new kit to the existing boardconstkit=board.addKit(Starter);// place the `generateText` node on the board.// for more information about this node type, see:// https://github.com/google/labs-prototypes/tree/main/seeds/llm-starter#the-generatetext-nodekit.generateText();
Hopefully, this approach will be fairly familiar and uncontroversial to folks who use JS libraries in their work. Now, onto the more hairy (wire-ey?) bits.
🧵 Wiring nodes
To wire nodes, I went with a somewhat unconventional approach. I struggled with a few ideas here, and ended up with a syntax that definitely looks weird, at least at first.
Here’s a brief outline of the crux of the problem. In Breadboard, a wire connects two nodes. Every node has inputs and outputs. For example, the `generateText` node that calls the PaLM API `generateText` method accepts several input properties, like the API key and the text of the prompt, and produces outputs, like the generated text.
So, to make a connection between two nodes meaningful, we need to somehow capture four parameters:
➡️ The tail, or node from which the wire originates. ⬅️ The head, or the the node toward which the wire is directed. 🗣️ The from property, or the output of the tail node from which the wire connects 👂 The to property, or the input of the head node to which the wire connects
To make this more concrete, let’s code up a very simple board:
import{Board}from"@google-labs/breadboard";// create a new boardconstboard=newBoard();// place input node on the boardconsttail=board.input();// place output node on the boardconsthead=board.output();
Suppose that next, we would like to connect property named “say” in `tail` to property named “hear” in `head`. To do this, I went with the following syntax:
// Wires `tail` node’s output named `say` to `head` node’s output named `hear`.tail.wire(“say->hear”,head);
Note that the actual wire is expressed as a string of text. This is a bit unorthodox, but it provides a nice symmetry: the code literally looks like the diagram above. First, there’s the outgoing node, then the wire, and finally the incoming node.
This syntax also easily affords fluent interface programming, where I can keep wiring nodes in the same long statement. For example, here’s how the LLM-powered calculator pattern from the post about AI patterns looks like when written with Breadboard library:
math.input({$id:"math-question"}).wire("text->question",kit.promptTemplate("Translate the math problem below into a JavaScript function named"+"`compute` that can be executed to provide the answer to the"+"problem\nMath Problem: {{question}}\nSolution:",{$id:"math-function"} ).wire("prompt->text",kit.generateText({$id:"math-function-completion"}).wire("completion->code",kit.runJavascript("compute->",{$id:"compute"}).wire("result->text",math.output({$id:"print"})) ).wire("<-PALM_KEY",kit.secrets(["PALM_KEY"])) ));
Based on early feedback, there’s barely a middle ground of reactions to this choice of syntax. People either love it and find it super-cute and descriptive (“See?! It literally looks like a graph!”) or they hate it and never want to use it again (“What are all these strings? And why is that arrow pointing backward?!”) Maybe such contrast of opinions is a good thing?
However, aside from differences in taste, the biggest downside of this approach is that the wire is expressed as a string: there are plenty of opportunities to make mistakes between these double-quotes. Especially in a strongly-typed land of TypeScript, this feels like a loss of fidelity – a black hole in the otherwise tight system. I have already found myself frustrated by a simple misspelling in the wire string, and it seems like a real problem.
I played briefly with TypeScript template literal types, and even built a prototype that can show syntax errors when the nodes are miswired. However, I keep wondering – maybe there’s an even better way to do that?
So here’s an invitation: if coming up with a well-crafted TypeScript/Javascript API is something that you’re excited about, please come join our little Discord and help us Breadboard folks find an even better way to capture graphs in code. We would love your help and appreciate your wisdom.
To make the asymptote and value niches framing a bit more concrete, let’s apply it to the most fun (at least for me) emergent new area of developer experience: the various developer tools and services that are cropping up around large language models (LLMs).
As the first step, let’s orient. The layer above us is AI application developers. These are folks who aren’t AI experts, but are instead experienced full-stack developers who know how to build apps. Because of all the tantalizing promise of something new and amazing, they are excited about applying the shiny new LLM goodness.
The layer below us is the LLM providers, who build, host, and serve the models. We are in the middle, the emerging connective tissue between the two layers. Alright – this looks very much like a nice layered setup!
Below is my map of the asymptotes. This is not a complete list by any means, and it’s probably wrong. I bet you’ll have your own take on this. But for the purpose of exercising the asymptotes framing, it’ll do.
🚤 Performance
I will start with the easiest one. It’s actually several asymptotes bundled into one. Primarily because they are so tied together, it’s often difficult to tell which one we’re actually talking about. If you have a better way to untangle this knot, please go for it.
Cost of computation, latency, availability – all feature prominently in conversations with AI application developers. Folks are trying to work around all of them. Some are training smaller models to save costs. Some are sticking with cheaper models despite their more limited capabilities. Some are building elaborate fallback chains to mitigate LLM service interruptions. All of these represent opportunities for AI developer tooling. Anyone who can offer better-than-baseline performance will find a sound value niche.
Is this a firm asymptote or a soft one? My guess is that it’s fairly soft. LLM performance will continue to be a huge problem until, one day, it isn’t. All the compute shortages will continue to be a pain for a while, and then, almost without us noticing, they will just disappear, as the lower layers of the stack catch up with demand, reorient, optimized – in other words, do that thing they do.
If my guess is right, then if I were to invest around the performance asymptote, I would structure it in a way that would keep it relevant after the asymptote gives. For example, I would probably not make it my main investment. Rather, I would offer performance boosts as a complement to some other thing I am doing.
🔓 Agency
I struggled with naming this asymptote, because it is a bit too close to the wildly overused moniker of “Agents” that is floating around in AI applications space. But it still seems like the most appropriate one.
Alex Komoroske has an amazing framing around tools and services, and it describes the tension perfectly here. There is a desire for LLMs to be tools, not services, but the cost of making and serving a high-quality model is currently too high.
The agency asymptote clearly interplays with the performance asymptote, but I want to keep it distinct, because the motivations, while complementary, are different. When I have agency over LLMs, I can trace the boundary around it – what is owned by me, and what is not. I can create guarantees about how it’s used. I can elect to improve it, or even create a new one from scratch.
This is why we have a recent explosion of open source models, as well as the corresponding push to run models on actual user devices – like phones. There appears to be a lot of AI developer opportunities around this asymptote, from helping people serve their models to providing tools to train them.
Is this value niche permanent or temporary? I am just guessing here, but I suspect that it’s more or less permanent. No matter how low the costs and latency, there will be classes of use cases where agency always wins. My intuition is that this niche will get increasingly smaller as the performance asymptote gets pushed upward, but it will always remain. Unless of course, serving models becomes so inexpensive that they could be hosted from a toaster. Then it’s anyone’s guess.
💾 Memory
LLMs are weird beasts. If we do some first-degree sinning and pretend that LLMs are humans, we would notice that they have the long-term memory (the datasets on which they were trained) and the short-term memory (the context window), but no way to bridge the two. They’re like that character from Memento: know plenty of things, but can’t form new memories, and as soon as the context window is full, can’t remember anything else in the moment.
This is one of the most prominent capability asymptotes that’s given rise to the popularity of vector stores, tuning, and the relentless push to increase the size of the context window.
Everyone wants to figure out how to make an LLM have a real memory – or at least, the best possible approximation of it. If you’re building an AI application and haven’t encountered this problem, you’re probably not really building an AI application.
Based on how I see it, this is a massive value niche. Because of the current limitation of how the models are designed, something else has to compensate for its lack of this capability. I fully expect a lot of smart folks to continue to spend a lot of time trying to figure out the best memory prosthesis for LLMs.
What can we know about the firmness of this asymptote? Increasing the size of the context window might work. I want to see whether we’ll run into another feature of the human mind that we take for granted: separation between awareness and focus. A narrow context window neatly doubles as focus – “this is the thing to pay attention to”. I can’t wait to see and experiment with the longer context windows – will LLMs start experiencing the loss of focus as their awareness expands with the context window?
Overall, I would position the slider of the memory asymptote closer to “firm”. Until the next big breakthrough with LLM design properly bridges the capability gap, we’ll likely continue to struggle with this problem as AI application developers. Expect proliferation of tools that all try to fill this value niche, and a strong contentious dynamic between them.
📐 Precision
The gift and the curse of an LLM is the element of surprise. We never quite know what we’re going to get as the prediction plays out. This gives AI applications a fascinating quality: we can build a jaw-dropping, buzz-generating prototype with very little effort. It’s phenomenally easy to get to the 80% or even 90% of the final product.
However, eking out even a single additional percentage point comes at an increasingly high cost. The darned thing either keeps barfing in rare cases, or it is susceptible to trickery (and inevitable subsequent mockery), making it clearly unacceptable for production. Trying to connect the squishy, funky epistemological tangle that is an LLM to the precise world of business requirements is a fraught proposition – and thus, a looming asymptote.
If everyone wants to ship an AI application, but is facing the traversal of the “last mile” crevasse, there’s a large opportunity for a value niche around the precision asymptote.
There are already tools and services being built in this space, and I expect more to emerge as all those cool prototypes we’re all seeing on Twitter and Bluesky struggle to get to shipping. Especially with the rise of the agents, when we try to give LLMs access to more and more powerful capabilities, it seems that this asymptote will get even more prominent.
How firm is this asymptote? I believe that it depends on how the LLM is applied. The more precise the outcomes we need from the LLM, the more challenging they will be to attain. For example, for some use cases, it might be okay – or even a feature! – for an LLM to hallucinate. Products built to serve these use cases will feel very little of this asymptote.
On the other hand, if the use case requires an LLM to act in an exact manner with severe downside of not doing so, we will experience precision asymptote in spades. We will desperately look for someone to offer tools or services that provide guardrails and telemetry to keep the unruly LLM in check, and seek security and safety solutions to reduce abuse and incursion incidents.
I have very little confidence in a technological breakthrough that will significantly alleviate this asymptote.
🧠 Reasoning
One of the key flaws in confusing what LLMs do with what humans do comes from the underlying assumption that thinking is writing. Unfortunately, it’s the other way around. Human brains appear to be multiplexed cognition systems. What we presume to be a linear process is actually an emergent outcome within a large network of semi-autonomous units that comprise our mind. Approximating thinking and reasoning as spoken language is a grand simplification – as our forays into using LLMs as chatbots so helpfully point out.
As we try to get the LLMs to think more clearly and more thoroughly, the reasoning asymptote begins to show up. Pretty much everyone I know who’s playing with LLMs is no longer using just one prompt. There are chains of prompts and nascent networks of prompts being wired to create a slightly better approximation of the reasoning process. You’ve heard me talk about reasoning boxes, so clearly I am loving all this energy, and it feels like stepping toward reasoning.
So far, all of this work happens on top of the LLMs, trying to frame the reasoning and introduce a semblance of causal theory. To me, this feels like a prime opportunity at the developer tooling layer.
This asymptote also seems fairly firm, primarily because of the nature of the LLM design. It would take something fundamentally different to produce a mind-like cognition system. I would guess that, unless such a breakthrough is made, we will see a steady demand and a well-formed value niche for tools that help arrange prompts into graphs of flows between them. I could be completely wrong, but if that’s the case, I would also expect the products that aids in creating and hosting these graphs will be the emergent next layer in the LLM space, and many (most?) developers will be accessing LLMs through these products. Just like what happened with jQuery.
There are probably several different ways to look at this AI developer experience space, but I hope this map gives you: a) a sense of how to apply the asymptotes and value niches framing to your problem space and b) a quick lay of the land of where I think this particular space is heading.
I have been thinking lately about a framing that would help clarify where to invest one’s energy while exploring a problem space. I realized that my previous writing about layering might come in handy.
This framing might not work for problem spaces that aren’t easily viewed in terms of interactions between layers. However, if the problem space can be viewed in such a way, we can then view our investment of energy as an attempt to create a new layer on top of an existing one.
Typically, new layers tend to emerge to fill in the insufficient capabilities of the previous layers. Just like the jQuery library emerged to compensate for consistency in querying and manipulating the document object model (DOM) across various browsers, new layers tend to crop up where there’s a distinct need for them.
This happens because of the fairly common dynamic playing out at the lower layer: no matter how much we try, we can’t get the desired results out of the current capabilities of that layer. Because of this growing asymmetry of effort-to-outcome in the dynamic, I call it “the asymptote” – we keep trying harder, but get results that are about the same.
Asymptotes can be soft and firm.
Firm asymptotes typically have something to do with the laws of physics. They’re mostly impossible to get around. Moore’s law appears to have run into this asymptote as the size of a transistor could no longer get any smaller.
Soft asymptotes tend to be temporary and give after enough pressure is applied to them. They are felt as temporary barriers, limitations that are eventually overcome through research and development.
One way to look at the same Moore’s law is that while the size of the transistor has a firm asymptote, all the advances in hardware and software keep pushing the soft asymptote of the overall computational capacity forward.
When we think about where to focus, asymptotes become a useful tool. Any asymmetry in effort-to-outcome is usually a place where a new layer of opinion will emerge. When there’s a need, there’s potential value to be realized by serving that need. There’s a potential value niche around every asymptote. The presence of an asymptote represents opportunities: needs that our potential customers would love us to address.
Depending on whether the asymptotes are soft or firm, the opportunities will look differently.
When the asymptote is firm, the layer that emerges on top becomes more or less permanent. These are great to build a solid product on, but are also usually subject to strong five-force dynamics. Many others will want to try to play there, so the threat of “race to the bottom” will be ever-present. However, if we’re prepared for the long slog and have the agility to make lateral moves, this could be a useful niche to play in.
The jQuery library is a great example here. It wasn’t the first or last contender to make life easier for Web developers. Among Web platform engineers, there was a running quip about a new Web framework or library being born every week. Yet, jQuery found its place and is still alive and kicking.
When the asymptote is soft, the layer we build will need to be more mercurial, forced to adapt and change as the asymptote is pushed forward with new capabilities from the lower layer. These new capabilities of the layer below could make our layer obsolete, irrelevant – and sometimes the opposite.
A good illustration of the latter is how the various attempts to compile C++ into Javascript were at best a nerdy oddity – until WebAssembly suddenly showed up as a Web platform primitive. Nerdy oddities quickly turned into essential tools of the emergent WASM stack.
Putting in sweat and tears around a soft asymptote usually brings more sweat and tears. But this investment might still be worth it if we have an intuition that we’ll hit the jackpot when the underlying layer changes again.
Having a keen intuition of how the asymptote will shift becomes important with soft asymptotes. When building around a soft asymptote, the trick is to look ahead to where it will shift, rather than grounding in its current state. We still might lose our investment if we guess the “where” wrong, but we’ll definitely lose it if we assume the asymptote won’t shift.
To bring this all together, here’s a recipe for mapping opportunities in a given problem space:
Orient yourself. Does the problem space look like layers? Try sketching out the layer that’s below you (“What are the tools and services that you’re planning to consume? Who are the vendors in your value chain?”), the layer where you want to build something, and the layer above where your future customers are.
Make a few guesses about the possible asymptotes. Talk to peers who are working in or around your chosen layer. Identify areas that appear to exhibit the diminishing returns dynamic. What part of the lower layer is in demand, but keeps bringing unsatisfying results? Map out those guesses into the landscape of asymptotes.
Evaluate firmness/softness of each asymptote. For firm asymptotes, estimate the amount of patience, grit, and commitment that will be needed for the long-term optimization of the niche. For soft asymptotes, see if you have any intuitions on when and how the next breakthrough will occur. Decide if this intuition is strong enough to warrant investment. Aim for the next position of the asymptote, not the current one.
At the very least, the output of this recipe can serve as fodder for a productive conversation about the potential problems we could collectively throw ourselves against.
My friend Dion asked me to write this down. It’s a neat little pattern that I just recently uncovered, and it’s been delighting me for the last couple of days. I named it “porcelains”, partially as an homage to spiritually similar git porcelains, partially because I just love the darned word. Porcelains! ✨ So sparkly.
The pattern goes like this. When we build our own cool thing on top of an existing developer surface, we nearly always do the wrapping thing: we take the layer that we’re building on top and wrap our code around it. In doing so, we immediately create another, higher layer. Now, the consumers of our thing are one layer up from the layer from which we started. This wrapping move is very intuitive and something that I used to do without thinking.
// my API which wraps over the underlying layer.constcallMyCoolService = async (payload) => {constmyCoolServiceUrl = "example.com/mycoolservice";returnawait// the underlying layer that I wrap: `fetch` (awaitfetch(url, {method:"POST",body:JSON.stringify(payload), }) ).json(); };// ...// at the consuming call site:constresult = awaitcallMyCoolService({ foo:"bar" });console.log(result);
However, as a result of creating this layer, I now become responsible for a bunch of things. First, I need to ensure that the layer doesn’t have too much opinion and doesn’t accrue its cost for developers. Second, I need to ensure that the layer doesn’t have gaps. Third, I need to carefully navigate the cheesecake or baklava tension and be cognizant of the layer thickness. All of a sudden, I am burdened with all of the concerns of the layer maintainer.
It’s alright if that’s what I am setting out to do. But if I just want to add some utility to an existing layer, this feels like way too much. How might we lower this burden?
This is where porcelains come in. The porcelain pattern refers to only adding code to supplement the lower layer functionality, rather than wrapping it in a new layer. It’s kind of like – instead of adding new plumbing, put a purpose-designed porcelain fixture next to it.
Consider the code snippet above. The fetch API is pretty comprehensive and – let’s admit it – elegantly designed API. It comes with all kinds of bells and whistles, from signaling to streaming support. So why wrap it?
What if instead, we write our code like this:
// my API which only supplies a well-formatted Request.constmyCoolServiceRequest = (payload) =>Request("example.com/mycoolservice", {method:"POST",body:JSON.stringify(payload), });// ...// at the consuming call site:constresult = await (awaitfetch(myCoolServiceRequest({ foo:"bar" })) ).json();console.log(result);
Sure, the call site is a bit more verbose, but check this out: we are now very clear what underlying API is being used and how. There is no doubt that fetch is being used. And our linter will tell us if we’re using it improperly.
We have more flexibility in how the results of the API could be consumed. For example, if I don’t actually want to parse the text of the API (like, if I just want to turn around and send it along to another endpoint), I don’t have to re-parse it.
Instead of adding a new layer of plumbing, we just installed a porcelain that makes it more shiny for a particular use case.
Because they don’t call into the lower layer, porcelains are a lot more testable. The snippet above is very easy to interrogate for validity, without having to mock/fake the server endpoint. And we know that fetch will do its job well (we’re all in big trouble otherwise).
There’s also a really fun mix-and-match quality to porcelain. For instance, if I want to add support for streaming responses to my service, I don’t need to create a separate endpoint or have tortured optional arguments. I just roll out a different porcelain:
// Same porcelain as above.constmyCoolServiceRequest = (payload) =>Request("example.com/mycoolservice", {method:"POST",body:JSON.stringify(payload), });// New streaming porcelain.classMyServiceStreamer {writable;readable;// TODO: Implement this porcelain. }// ...// at the consuming call site:constresult = awaitfetch(myCoolServiceRequest({ foo:"bar", streaming:true }) ).body.pipeThrough(newMyServiceStreamer());forawait (constchunkofresult) {process.stdout.write(chunk); }process.stdout.write("\n");
I am using all of the standard Fetch API plumbing – except with my shiny porcelains, they are now specialized to my needs.
The biggest con of the porcelain pattern is that the plumbing is now exposed: all the bits that we typically tuck so neatly under succinct and elegant API call signatures are kind of hanging out.
This might put some API designers off. I completely understand. I’ve been of the same persuasion for a while. It’s just that I’ve seen the users of my simple APIs spend a bunch of time prying those beautiful covers and tiles open just to get to do something I didn’t expect them to do. So maybe exposed plumbing is a feature, not a bug?
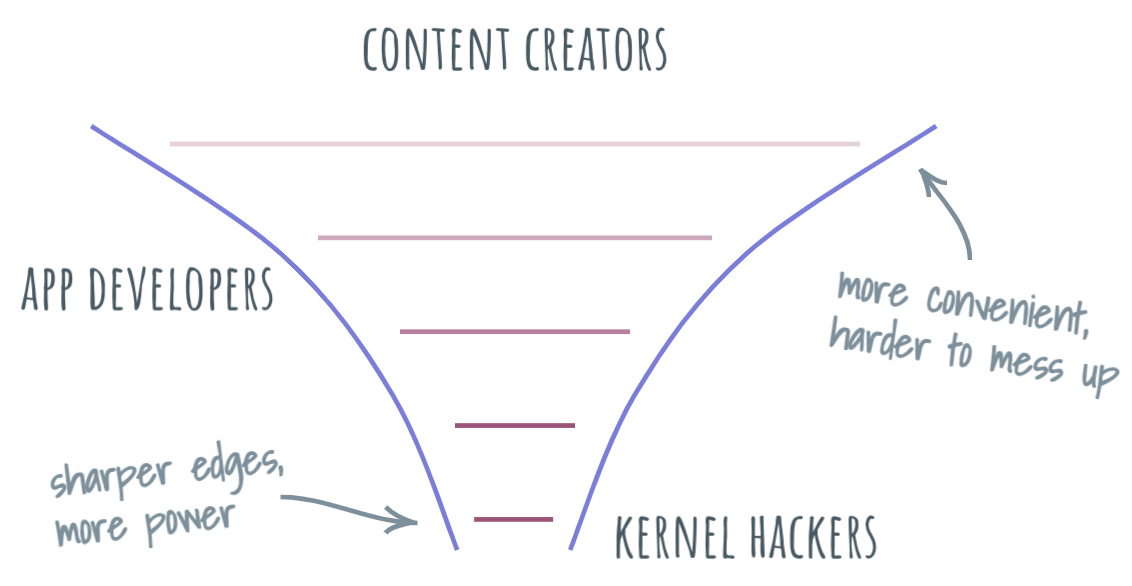
If I ever chatted with you about developer experience in person, I’ve probably drawn the developer funnel for you on the whiteboard. For some reason, I always draw it as a funnel — but any power-law visualization can suffice. As an aside, I do miss the whiteboards.
At the bottom of the funnel, there are a rare few who know how to speak to computers as directly as humans can. Their perspective on writing data to storage involves programming a controller. As we travel a bit higher, we’ll find a somewhat larger number peeps who write hardcore code (usually C/C++, and more recently, Rust) that powers operating systems. Higher still, the power law kicks into high gear: there are significantly more people with each click. Developers who write system frameworks are vastly outnumbered by developers who consume them, and there are orders of magnitudes more of those who write Javascript. They are still entirely eclipsed by the number of those who create content.
With each leap in numbers, something else happens — the amount of power passed upward diminishes. Each new layer of abstraction aims to reduce the underlying complexity of computing and in doing so, also collapses the number of choices available to developers who work with that layer. Try to follow the rabbit trail of setting a cookie value, a one-liner in Javascript — and a massive amount of work in the browser that goes into that. Reducing complexity makes the overall mental model of computing simpler and easier to learn, which helps to explain the growing number of developers.
This funnel can be a helpful framing for a conversation about desired qualities of the API. Do we want to have rapid growth? Probably want to be aiming somewhere higher in the funnel, designing convenient, harder to mess up APIs. Want to introduce powerful APIs and not worry about the sharper edges? Expect only a small number of consumers who will understand how to use them effectively.
I’ve been feeling a little stuck in my progress with the Four Needs Framework, and one thing I am trying now is reframing my assumptions about the very basics of the framework. Here’s one such exploration. It comes from the recent thinking I’ve done around boundaries and relationships, a sort of continuation of the Puzzle Me metaphor. In part, the insight here comes from ideas in César Hidalgo’s Why Information Grows and Lisa Feldman Barrett’s How Emotions Are Made.
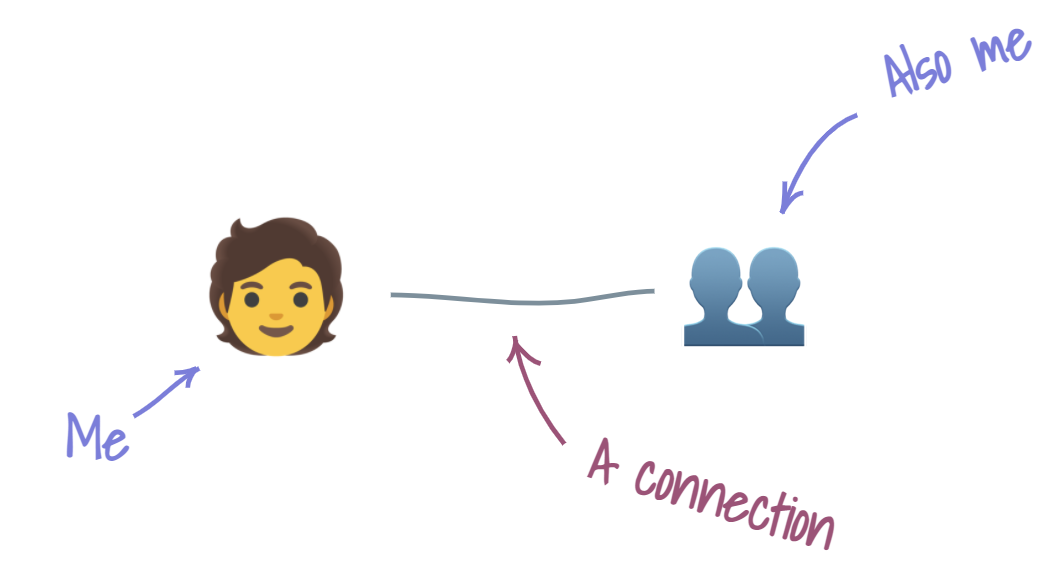
My conscious experience is akin to navigating a dense, messy network of concepts. I construct reality by creating and organizing these concepts. One way in which I organize concepts is by defining relationships between them and me. The nature of the relationship can be viewed as a continuum of judgements I can make about whether a concept is me or not me. For concepts that are closer to “me” in this continuum, I see my relationship with them more like a connection.
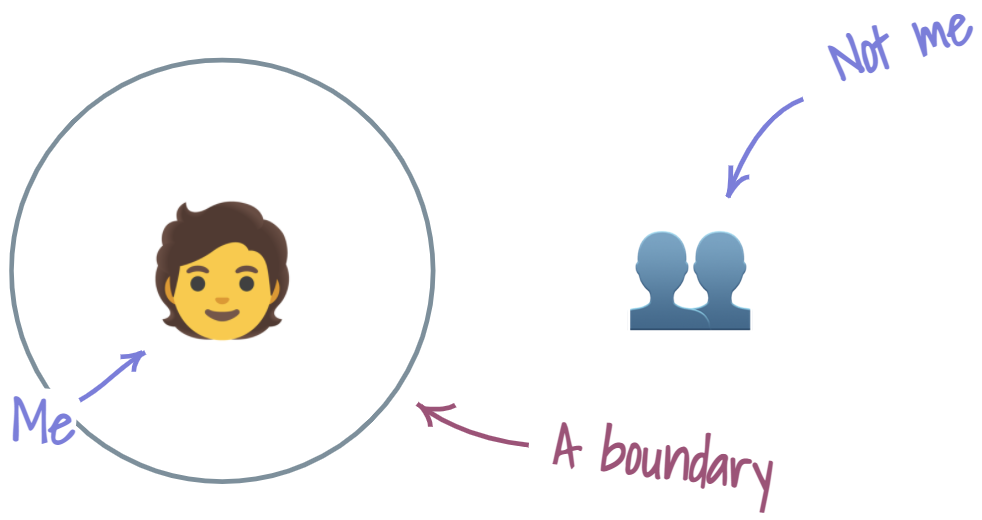
For concepts that are closer to “not me,” I judge the relationship with them as more like a boundary.
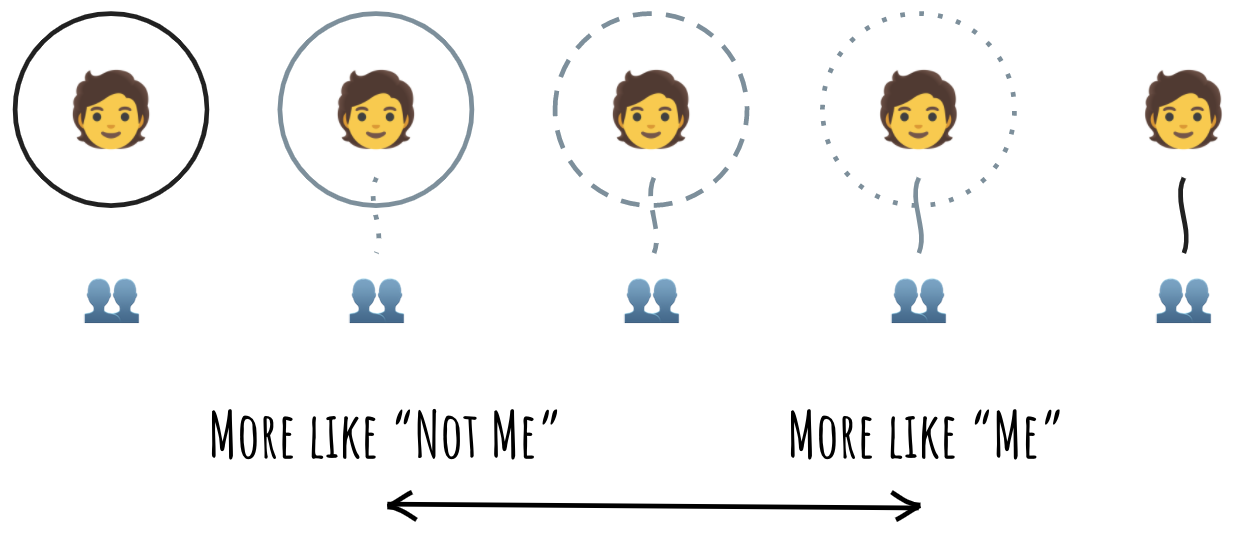
Sometimes the choice is clearly “me”, like my Self. Sometimes it’s nearly perfectly “me”, like my nose. Sometimes the choice is clearly not me. For example, last time I touched a hot stove I suddenly became informed that it definitely was not me. Sometimes, the position is somewhere in the middle. My bike is not me, since it’s not actually my body part, but it can feel like an extension of me on a Sunday ride.
Think of this continuum of judgements as a continuum between boundary and connection. The more I feel that the concept is “me,” the closer it is to the “connection” end of the continuum. The more I feel that the concept is “not me,” the farther it sits toward the “boundary” end of the continuum.
In this framing, the choices I make about my relationship with concepts are points on this continuum. As I interact with concepts, I define my relationship with them by picking the spot on this continuum based on my interaction experiences.
This is where the next turn in this story comes. It seems that some concepts will naturally settle down into one spot and stay there. “Hot stove” will stick far toward the “boundary” end of the continuum. “My bike” will be closer to “connection.” On the other hand, some concepts will resist this simple categorization. Depending on the interaction experience, they might appear as one of several points on the continuum. They might appear as a range, or maybe even a fuzzy cloud that covers part or the entire continuum.
The concepts that settle down into steady spots become part of my environment: they represent things that I assume to be there. They are my reference points. Things like ground, gravity, water, and so on take very little effort to acknowledge and rely on, because our brains evolved to operate on these concepts exceptionally efficiently.
The concepts whose position on the continuum is less settled are more expensive to the human brain to interact with. Because our brains are predictive devices, they will struggle to make accurate predictions. By expending extra energy, our brains will attempt to “make sense” of these concepts. A successful outcome of this sense-making process is the emergence of new concepts. Using the hot stove example from above, the brain might split the seemingly-binary concept of a “stove that sometimes hurts and sometimes doesn’t” into “hot stove” and “cold stove.” This new conceptual model is more subtle and allows for better prediction. It is also interesting to note how concept-splitting retains transitive relationships (“hot stove” is still a “stove”) and seems to form a relational network for stable concepts.
There’s also a possibility of a stalemate in this seemingly mechanical game of concept-splitting: a relationship polarity. A relationship polarity occurs when the concept appears to resist being split into a connected network of more stable concepts.
Sometimes I feel cranky, and sometimes I feel happy. Is it because I am hungry? Sometimes. Is it because of the weather? Sometimes. Relationship polarities are even more energy-consuming, because they produce this continuous churn within the relational network of concepts. My mind creates a model using one set of concepts, then the new experiences disconfirm it, the mind breaks it down, and creates another model, and so on. There’s something here around affect as well: this churn will likely feel uncomfortable as the interoceptive network issues warnings about energy depletion. In terms of emotions, this might manifest as concepts of “dread”, “stress”, “anxiety”, etc.
What was most curious for me is how a relationship polarity arises naturally as a result of two parties interacting. The key insight here is in adaptation being a source of the seeming resistance. As both you and I attempt to construct conceptual models of each other, we adjust our future interactions according to our models. In doing so, we create more opportunities for disconfirming experiences to arise, spurring the concept churn. The two adaptive parties do not necessarily need to be distinct individuals. As I learn more about myself, I change how I model myself, and in doing so, change how I learn about myself.