I was working on decision-making frameworks this week and had a pretty insightful conversation with a colleague, using the Cynefin framework as context. Here’s a story that popped out of it.
Many (most?) challenging decisions-requiring situations seem to reside in this liminal space between Complex and Complicated quadrants. We humans generally dislike the unpredictability of the complex space, so we invest a lot of time and energy into trying to shift the context: try to turn a complex situation into a complicated one. Especially in today’s business environments, we have a crapload of tools (processes, practices, metrics, etc.) to tackle complicated situations, and it just feels right to quickly get to the point where a problem becomes solvable. This property of solvability is something that is acquired as a result of transitioning through the Complex-Complicated liminal space. I use the word “framing” to describe this transition: we take a phenomenon that looks fuzzy and weird, then we frame it in terms of some well-established metaphors. Once framed, the phenomenon snaps into shape: it becomes a problem. Once a problem exists, it can be solved using those nifty business tools.
This transformation is lossy. Some subtle parts of the phenomenon’s full complexity become invisible once it becomes “the problem.” If I am lucky with my framing, these subtle parts will remain irrelevant. In the less happy case, the subtle parts will continue influencing the visible parts — the ones we see as “the problem.” We usually call these side effects. With side effects, the problem will appear to be resisting our attempts to solve it. No matter how much we try, our solutions will create new problems, new side effects to worry about.
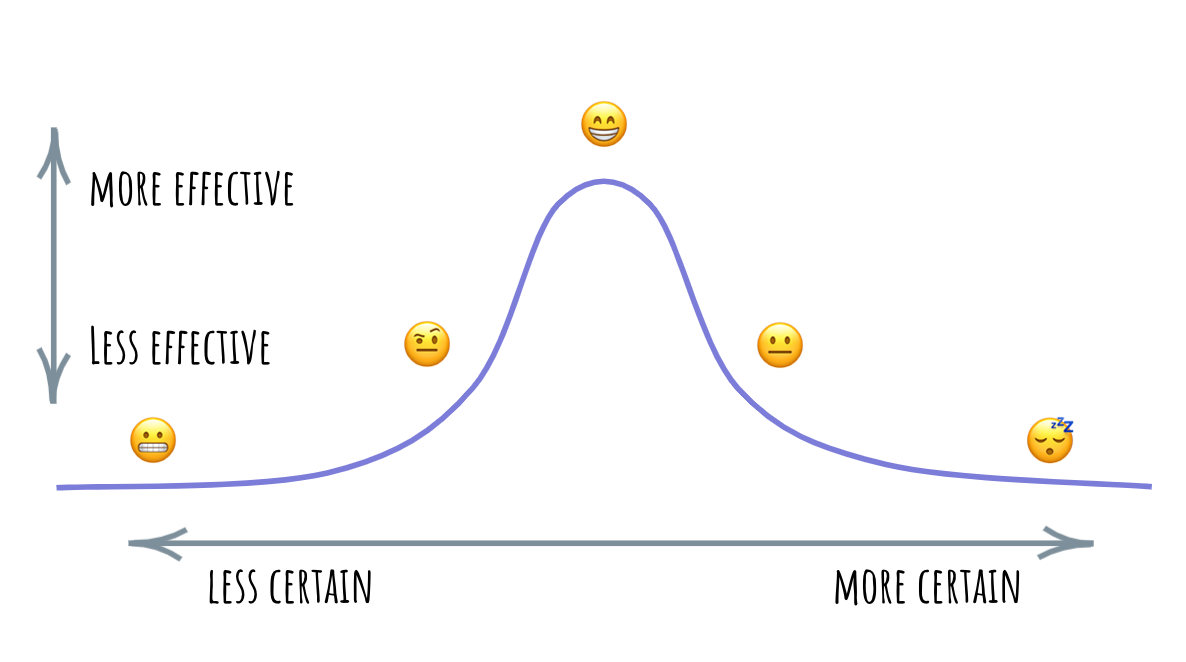
In this story, it’s pretty evident that effective framing is key to making a successful Complex-Complicated transition. Further, it’s also likely that framing is an iterative process: once we encounter side effects, we are better off recognizing that what we believe is “the problem” might be a result of ineffective framing — and shifting back to complex space to find a more effective one.
My colleague had this really neat idea that, given the multitudes of framings and problems we collectively track in our daily lives, it might be worth tagging the problems according to the experienced effectiveness of their framing. If a problem is teeming with side-effects, the framing has “not settled yet” — it’s the best framing we’ve got, but approach it lightly, do seek out novel ways to reframe the phenomenon. Decisions based on this framing are unlikely to stick or bear fruit. Conversely, settled framings are the ones that we didn’t have to adjust in a while and are consistently allowing us to produce side-effect free results. Here, decisions can be proceduralized and turned into best practices.