What would it be like to work in a team that experiences no jank? Do you have a reference point, perhaps a memory of the time when your organization’s flow felt like a flawless jazz session? Or maybe a picture of some brighter future? If you do, I’d like to tune into the yearning for that moment and bring this series to its close. Let’s imagine ourselves jankless.
Not to be flip about it, but a sure way to eliminate jank is to remove intention. When we are perfectly content with the environment around us, the “what is” and “what should be” are the same. Our expectation gradient is zero. Frankly, this is never true for us humans: our aim is always a bit off that perfect Zen spot. We always want something, and even wanting to be in the Zen spot is an intention. So there’s that.
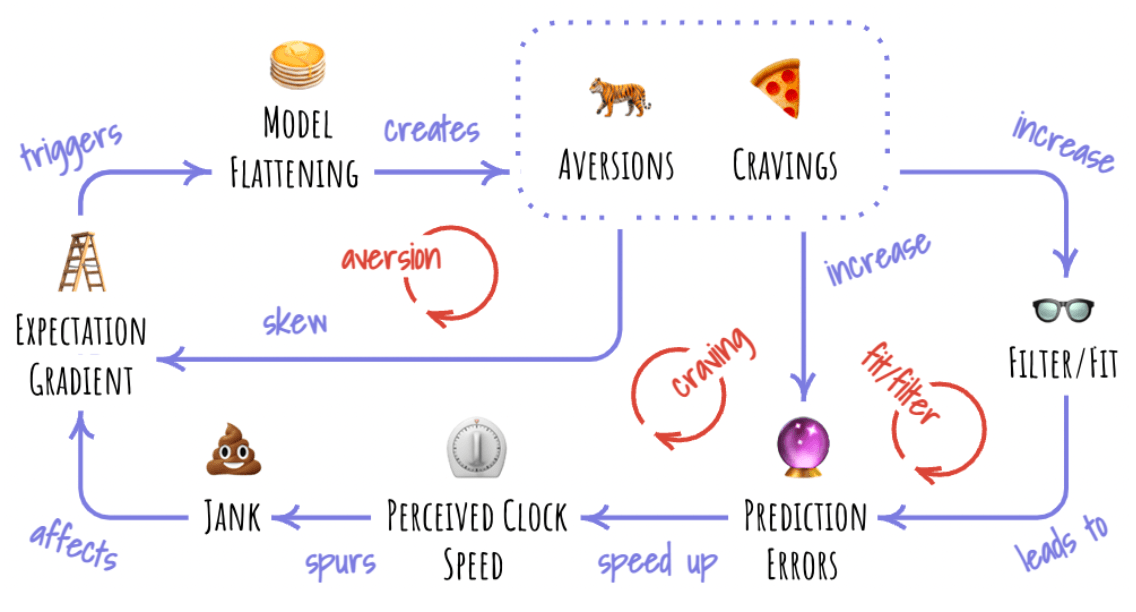
However, there’s something in that idyllic absence of intention that can serve as our guidelight. What is our level of attachment to our intentions? If our organizational objectives feel existential, we might be subject to the trove of aversions and cravings we’ve accumulated in the models of our environment. The compounding loops we’ve talked about earlier are always at work, and it’s on us to make them object. Let’s go through each step of the OODA loop and see what tools and practices might help us do that. The common tactic we’ll use is similar to a technique in sailing, when the crew leans out of the boat to decrease its roll. With compounding loops always present, we want to keep carefully counterbalancing them.
When we Observe the environment, the fit/filter cycle is the one to keep an eye on. Examining our organization, here are some questions we can to ask ourselves:
- What are the teams’ processes to understand the environment? If they are centralized and highly operationalized, they are likely subject to filtering.
- Do we have a way to measure our prediction error? How well are we equipped to look at the mistakes we made? How well are our processes guiding us to incorporate them into our model of environment?
- Are there norms around making sure that multiple perspectives are considered? Are divergent perspectives cherished?
- How fixed are the metrics? How well-understood are they? Well-settled metrics are a good way to spot the work of the fit/filter cycle. The environment is always in flux, and metrics that don’t evolve tend to become meaningless over time.
- Does the organization deal with the reality of blindspots? Do the team deny their existence? Are there practices to assess their state and maybe even dig into them?
As we Orient, examining our prediction error and updating our model of “what is” to reduce it, we contend with all three cycles. Here, the biggest bang for the buck is likely in focusing on the care with which we construct the model.
To make things interesting, the collective model of the environment is rarely legible in an organization. If I went looking for it, I would not find a folder labeled: “The model of our environment. Update on every OODA cycle.” Instead, organizations tend to model the environment through the totality of their structure and people within it. Norms that people have, incentives, principles, and regulations that they adhere to, connections they keep, practices they maintain – all are part of the model. To dance with the compounding loops, we want to bring the notion of the shared mental model to the forefront:
- Do the team and its leadership grasp the idea of a shared mental model? Do they recognize that Conway’s law is largely about shared mental models?
- Are there practices and norms to maintain and expand the shared mental model? How do team leads invest into ensuring that everyone on the team roughly sees the same picture of the environment?
- Are there means to estimate the consistency of the shared mental model across the organization? Are there markers in place to signal when the consistency is low?
- Are there boundaries around the shared mental model, with some people having no access to it? Having boundaries isn’t necessarily a bad thing, but not knowing why these boundaries exist is a sign they were put in place by cravings/aversions.
- Do we hold “what is” and “what should be” models separately? Do we have a way to sense the amount of wishful thinking that creeps into the “what is” model, like instances of “solutions looking for problems?”
While Deciding, we hold and update the “what should be” model, picking the best choice to steer toward it. We are once again buffeted by the full force of all three compounding loops. The prerequisite is the quality of the model we constructed at the previous step. If the quality of the model is low, decisions become much harder to make:
- When we make decisions, do we typically have a rich and diverse set of options to mull over? If not, this might be a sign that our Orient step needs a bit more extra TLC.
Provided that we did a decent job of that while Orienting, we can zoom in on discerning intention. A common marker of adulthood is “knowing what you want and what you don’t want.” A social commentary on how rare this is aside, it is quite easy to lose sight of that in a team. We rarely hold one unified collective intention, there are usually many, often in tension with each other. The strength of this tension is controlled by the mass cravings and aversions we accumulate:
- Does your organization have a way to explore its own cravings and aversions? Are there means by which you and your teammates can have candid conversation about the organization’s unspeakables and comfort objects?
- Do we have a clear sense of our stated intention? Does it span longer than the rate of most of our OODA loops? Do we have a way to communicate it? Do we have a way of knowing how well it is shared across the team?
- Does the team have a sense of how far its stated intentions diverge from the one they manifest? Do we deny the divergence exists? Do we accept its existence? Do we have practices to spot instances of it?
- Do we have a productive way to talk about the effects of model flattening? Do we shun the subject altogether? Do we push it into the corner of “well-being,” alongside other squishy topics like “team culture?”
Finally, when we Act, we mobilize and expend the energy we estimated and commit to the option we picked in the Deciding step. This is where the rubber meets the road and the next round of prediction errors is discovered. The outcomes here are born out of the previous steps, so the questions that arise will mostly echo that:
- Do we have a way to assess how much our effort estimates and the actual effort compare over time? Are our operational practices aware that these gaps are effects of model flattening? Does our assessment of prediction error account for them?
- How well do we do in sustaining our commitment to the decisions we made? Does the organization understand that wavering in commitment could indicate high divergence of stated and manifested intention? Are there processes in place to feed this insight back into the future Decide steps?
These are just some of the questions that came to my mind when considering jank in teams. Answering them can easily fill a book. And now I am curious. What questions did I miss? What possible answers popped into your head? What other compounding loops did you spot? If you are struggling with jank in your organization, did this series open up a new space of opportunities for you? It certainly did for me. When I set out to write a series of articles on the OODA loop, I had a somewhat different direction in mind – but reasoning through it with you helped me take it to this much more satisfying point. Thank you.