At the core of the OODA loop is the concept of a model. To create space for exploring it in depth, we’ll make a tiny little digression back into — you guessed it! — graphics rendering technology.
With my apologies to my colleagues — who will undoubtedly make fun of me for such an incredibly simplified story — everything you see on digital screens comes from one of the two modes of rendering: the immediate or the retained modes.
The immediate mode is the least complicated of the two. In this mode, the entirety of the screen is rendered from scratch every time. Every animation frame (remember those from the jank chapter?) is produced anew. Every pixel of output is brand new for each frame.
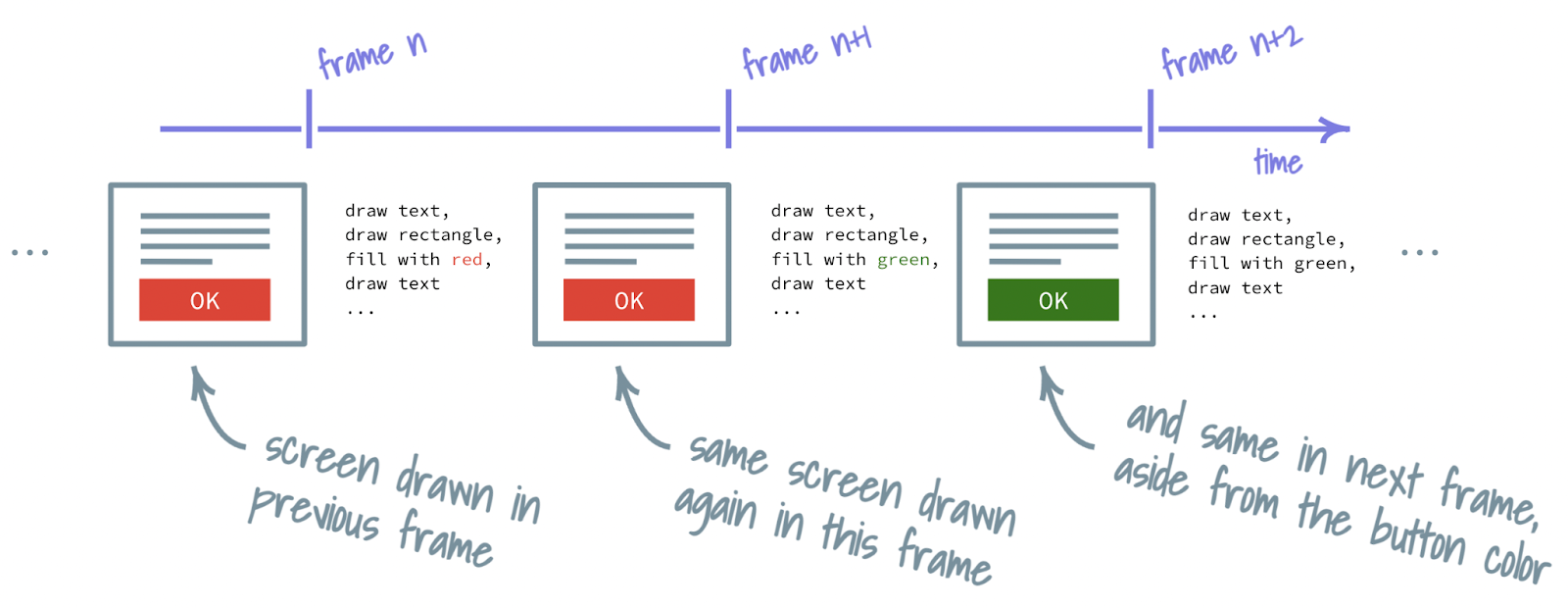
You might say: yeah, that seems okay — what other way could there be? Turns out, the immediate mode can be fairly expensive. “Every pixel” ends up being a lot of pixels and it’s hard to keep track of them, yet alone orchestrate them into user interfaces. Besides, many pixels on the screen stay the same from frame to frame. So clever engineers came up with a different mode.
In retained mode, there exists a separate model of what should be presented on screen. This model is usually an abstraction (a data structure as engineers might call it) that’s easy to examine and tweak and it is retained over multiple frames (hence the “retained” in the name). Such setup allows for partial changes: find and update only the parts of the model that need to change and leave the rest the same. So, when we want a button to turn a different color, the only part that has to be changed is the one representing the button’s color.

Both modes have their advantages and disadvantages. The immediate mode tends to need more effort and capacity to pay attention to the deluge of pixels, but it also offers a fairly predictable time-to-next-frame: if I can handle all these pixels for this frame, I can do so for the next frame. The retained mode can offer phenomenal benefits in saving the effort and do wonders when we have limited capacity. It also yields a “bursty” pattern of activity: for some frames, there’s no work to be done, while for others, the whole model needs to be rejiggered, causing us to blow the frame budget and generate jank.

This trade-off between unpredictable burstiness and potential savings of effort is at the crux of most modern UI framework development. The key ingredient in this challenge is designing how the model is represented. How do elements of the screen relate to each other? What are the possible changes? How to make them inexpensive? How to remain flexible when new kinds of changes emerge?
The story of Document Object Model (DOM) can serve as a dramatic illustration. Born as a way to represent documents at the early beginning of Web, DOM has a strong bias toward the then-common metaphor of print pages: it’s a hierarchy of elements, starting with the title, body, headings, etc. As computing moved on from pages towards more interactive, fluid experiences, this bias became one of the greatest limiting factors in the evolution of the Web. Millennia — hell, probably eons — of collective brain-racking had been invested into overcoming these biases, with mixed results. Despite all the earnest effort, jank is ever-present in the Web. Unyieldingly, the original design of the model keeps bending the arc of the story toward the 1990s, generating phenomenal friction in the process.
In a weird poetic way, the story of DOM feels like the story of humanity: the struggle to overcome the limitations imposed by well-settled truths that are no longer relevant.
One thought on “Retained and immediate mode”