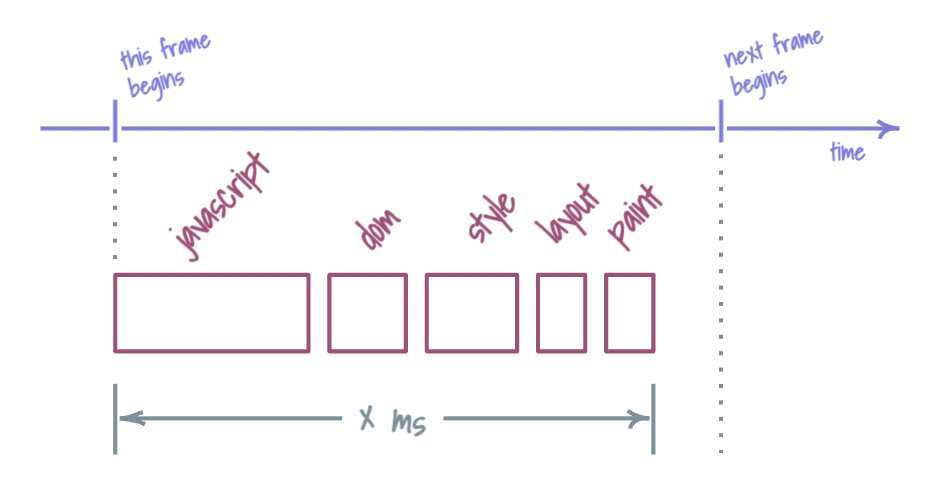
As it usually happens, we find ourselves in a conundrum. When managing jank, do we focus on the accuracy of our predictions or do we try to stay on pace with the clock? There does not seem to be a good answer — and trust me, “both” rarely feels helpful in the middle of the OODA cycle. It’s an iron triangle of seemingly impossible constraints. Given our current capacity as constant, we have to pick one of the two others: time or accuracy.

Each presents two different configurations for the OODA loop: I’ll call them the OOda loop and the ooDA loop (note the capitalization).
Leaning toward the OOda loop, we spent most of our budget trying to perfect the model, favoring the Observe-Orient steps. We try to “consider all possibilities” and “look at the whole picture” when leaning toward this side of the spectrum. We hesitate to engage, hoping that the nature of the environment will reveal itself to us if we just keep our eyes peeled.

In the extreme, this configuration turns into the OO loop. We are subject to our “flight” instinct. We zoom out as wide as possible, trying to find ways out of the situation we’re currently in, gripped by the anxiety that comes with trying to consume the entirety of the environment. Everyone and everything is a potential threat, and every part of the environment hides nasty surprises. Every possible action looks like a wrong move. There is no escape.
This configuration produces jank that is immediately visible and seen, rarely a micro jank. Skipping a move is a big deal — and also a form of action. To collect more information about the environment for each iteration of the cycle, we need to act. Missing our opportunity to do so reduces effectiveness of our Observe-Orient steps. Despite our best and widest stares at the world, we are passive participants and our learning is limited to what is seen. The “analysis paralysis” is a common description of a team that is veering too hard onto this side.
In the ooDA loop, we forget — or willfully ignore — that the model might not be accurate. We concentrate our energy on the Decide-Act part of the process. If someone is calling for “bias toward action,” they are probably looking to move closer to this configuration. We lose sight of our model being just a fanciful depiction of the environment. It feels like “we’ve got it,” we finally “figured it out,” and now it’s time to seize the moment. All we have to do is “create order from chaos.”

At the very extreme is the DA loop, when we’re driven entirely by our “fight” instinct. Here, our vision tunnels, and we only see simplified caricatures of the environment. A driver who just cut us off in traffic is a “stupid moron.” A colleague who said something we don’t agree with in a key meeting — a “backstabber.”
The ooDA configuration feels good at first. Asserting that the environment is “solved,” we gain a sense of certainty and confidence. Unfortunately, our prediction error rate tends to compound, because the model is being neglected — with each new cycle, we plow farther and farther away from reality. This compounding results in exponential growth in jank. We already know how this ends. From inside the organization, DA feels like one fire after another, sudden and unexpected. When teams are caught in constant fire-fighting and struggling to get out of one mess, then falling straight into another — chances are, they are favoring the ooDA loop’s end of the spectrum.
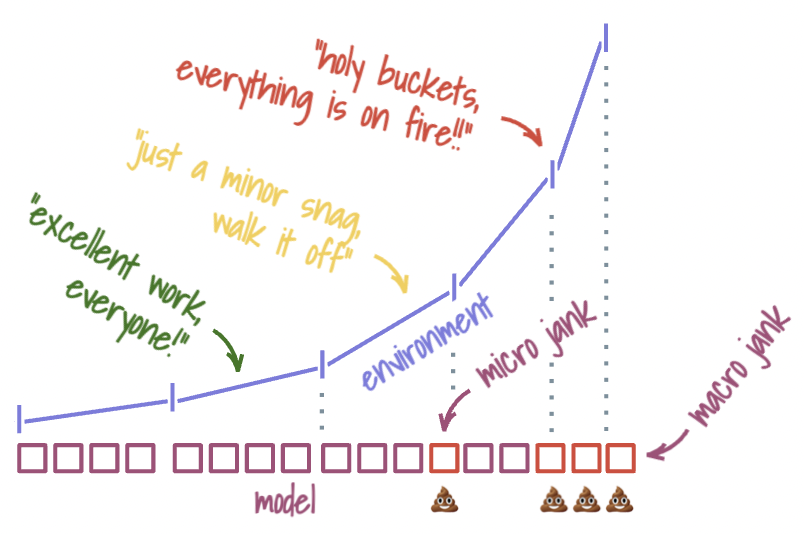
Neither of these extremes is a pleasant place to be, so organizations rarely spend time sitting in any of them. Instead, they lurch from one end to the other. The analysis paralysis gives way to “time for decisive action,” which is followed by “need to regroup and reassess” and so on. And in the process, teams pipe out jank like the smokestacks of the industrial revolution.
Individually, we all have our go-to OODA configuration as well. It is helpful to know our biases. For example, my first instinct is to shift to OOda, often in unproductive ways. Some folks I know prefer the more Leroy Jenkins style of ooDA, and recognizing how we might react in various situations helps us collaborate and reduce the collective lurching from one extreme to another.









 Since I’ve just concocted a different way to look at the OODA loop, I might as well add another twist. Unlike in Boyd’s original military context, OODA jank is not lethal for most organizations. It is something that happens commonly, perhaps many times over.
Since I’ve just concocted a different way to look at the OODA loop, I might as well add another twist. Unlike in Boyd’s original military context, OODA jank is not lethal for most organizations. It is something that happens commonly, perhaps many times over.