I’ve been thinking about the limits to seeing, and this diagram popped into my head. It feels like there’s more here, but I am not there yet. I thought I’d write down what I have so far.
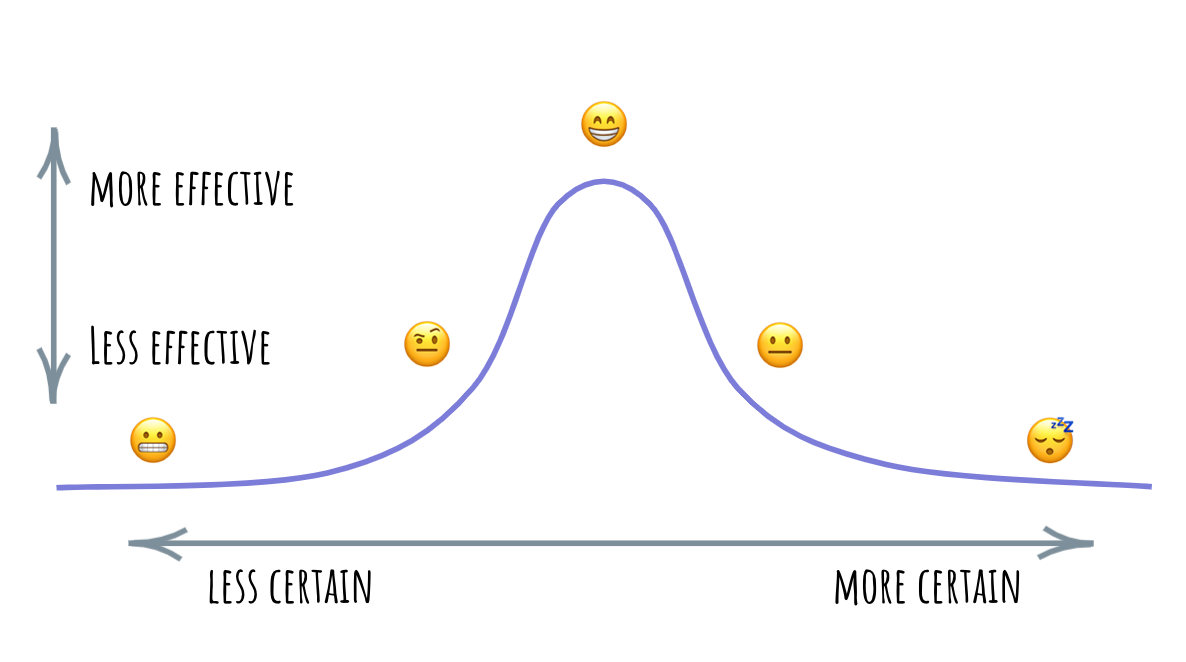
There’s something about the relationship between the degree of certainty we have in knowing something and our effectiveness applying that knowledge. When we’ve just encountered an unknown phenomenon — be that a situation or a person — we tend to be rather ineffective in engaging with it. Thinking of it in terms of constructed reality, our model of this phenomenon generates predictions that are mostly errors: we think it will go this way, but it goes completely differently. “I don’t get it. I thought he’d be glad I pointed out the problem with the design.” Each new error contributes to improving the model and, through the interaction with the phenomenon, we improve our prediction rate and with it, our certainty about our knowledge of the phenomenon. “Oh, turns out there’s another tech lead who actually makes all the calls on this team.” Here, our effectiveness of applying the knowledge seems to climb along with the improvements. At some point, our model gets pretty good, and we reach our peak effectiveness, wielding our knowledge skillfully to achieve our aims. This is where many competence frameworks stop and celebrate success, but I’ve noticed that often, the story continues.
As my prediction error rate drops below some threshold, the model becomes valuable: the hard-earned experiential knowledge begins to act as its own protector. The errors that help refine the model are rapidly incorporated, while the errors that undermine the model begin to bounce off. Because of this, my certainty in the model continues to grow, but the effectiveness slides. I begin to confuse my model with my experiences, preferring the former to the latter. “She only cares about these two metrics!” — “What about this other time… “ — “Why are we still talking about this?!” Turns out, my competence has a shadow. And this shadow will lull me to sleep of perfect certainty… until the next prediction error cracks the now-archaic model apart, and spurs me to climb that curve all over again.
For some reason, our brains really prefer fixed models — constructs that, once understood, don’t change or adapt over time. A gloomy way to describe our lifelong process of learning would be as the relentless push to shove the entire world into some model of whose prediction rate we are highly certain. And that might be okay. This might be the path we need to walk to teach ourselves to let go of that particular way of learning.