I’ve had this realization about myself recently, and it’s been rather useful in gaining a bit more understanding about how my mind works. I am writing it down in hopes it would help you in your own self-reflections.
The well-worn “Writing to think” maxim is something that’s near and dear to my heart: weaving a sequential story of the highly non-linear processes that are happening in my mind is a precious tool. I usually recommend developing the muscle for writing to think as a way to keep our thoughts organized to my colleagues and friends. Often, when I do, I am asked: “What do I write about?”
It’s a good question. At least for me, the ability to write appears to be closely connected to the space in which I am doing the thinking. It seems like the whole notion of “writing to think” might also work in reverse: when I don’t have something to write about, it might be a signal that my thinking space is fairly small or narrow.
There might be fascinating and very challenging problems that I am working on. I could be spending many hours wracking my brain trying to solve them. However, if this thinking doesn’t spur me to write about it, I am probably inhabiting a rather confined problem space.
I find that writing code and software engineering in general tend to collapse this space for me. Don’t get me wrong, I love making software. It’s one of those things that I genuinely enjoy and get a “coder’s high” from.
Yet, when doing so, I find that my thoughts are sharply focused and narrow. They don’t undulate and wander in vast spaces. They don’t get lost just for the sake of getting lost. Writing code is about bringing an idea to life. It’s a very concretizing process. Writing code is most definitely a process of writing to think, but it’s more of “writing it”, rather than “writing about it”.
The outcome is a crisp – albeit often spaghetti-like – set of instructions that are meant to be understood by a machine, which for all its complicatedness is a lot less complex than a human mind.
On the other hand, when I was doing more strategy work a few years back, I found myself brimming with ideas to write down. It was very easy to just knock out a post – nearly every idea I had was begging to be played with and turned into a story to share. I was in the wide-open space of thinking among people, and particularly long-term horizon, broad thinking, and wandering.
Nothing’s wrong with inhabiting smaller problem spaces for a little while. However, it’s probably not something I would pick as the only way of being. “Inhabiting” brings habits, and habits entrench. Becoming entrenched in smaller problem spaces means that the larger spaces become less and less accessible over time, resulting in strategic myopia.
It seems that to avoid such a diagnosis, we’ve gotta keep finding ways to think in spaces big enough to spur us to write. To use an analogy, “writing to think” is like developing a habit of brushing our teeth, and “thinking to write” is a way to check if we indeed follow this habit. If we find ourselves struggling to write, then maybe we need to broaden the problem space we inhabit.
An insightful conversation with a colleague inspired me to articulate the distinction between velocity and agility – and all that implies. When I talked about velocity in the past, I sort of elided the fact that agility, or the ability to change direction at a given velocity, plays a crucial role in setting organizations for success in certain conditions. I also want to disclaim that the definition of “agility” I use here is only loosely related to the well-known/loved/hated agile methodologies.
The example I’ve used in the past is that of a zodiac boat and an aircraft carrier. Though they are capable of roughly going at the same velocity, their agility is dramatically different. The zodiac boat’s maneuverability is what gives it a decisive advantage in an environment where the situation changes rapidly. On the other hand, an aircraft carrier is able to sustain velocity for much longer periods of time, which enables it to travel around the globe.
In engineering teams, velocity and agility are often used interchangeably, and I am quite guilty of doing this as well. Only in retrospect I am realizing why some teams that I’ve worked both with (and next to) looked and acted so differently. They were valuing, respectively, velocity or agility.
When the team favors velocity, it invests significantly into its capacity to achieve maximum sustained speed for the longest possible time. Decision-making and engineering processes, tools and infrastructure all feel like that of an aircraft carrier, regardless of the team’s actual size. It’s like the question on everyone’s mind is: “Can we cross the Pacific Ocean? How many times over?” The team is designed to go far, even if that means sacrificing some velocity to its robustness.
For instance, the Blink team I led a while back was all about velocity, borrowing most of its ethos from Google engineering culture. We designed our infrastructure to enable us to ship directly from trunk through diligent test coverage and a phenomenal build system (we built our own!), we followed the practice of code reviews and the shipping process. We talked about how this team was built to run for multiple decades.
This was (and a decade later, still is), of course, the right fit for that project. Rendering engines represent highly overconstrained, immensely complex systems of a relatively well-defined shape. The team that ships a rendering engine will not one day decide to do something completely different. The word “velocity” in such a team is tightly coupled with achieving predictable results over a long period of time.
However, when the final shape of the value niche is still unknown, and the product-market fit is something we only wistfully talk about, a different structure is needed. Here, the engineering team needs to lean into agility. When they do so, the project will act very differently. It will be more like a zodiac boat: not built to run forever, but rather to zig and zag quickly.
A project structured like a zodiac boat will have alarmingly few processes and entrenched practices. “What? They don’t do code reviews?” The trunk might be unshippable for periods that would be unacceptable by any standards of an aircraft carrier team. The codebase will have large cheese holes in implementation and test coverage, with many areas only loosely sketched. In a zodiac boat project, everything is temporary, and meant to shift as soon as a new promising approach is discovered.
Such projects are also typically small-sized. Larger teams means more opinions and more coordination headwinds, so zodiac boat projects will favor fewer folks who deeply understand the code base and have no problem diving in and changing everything. They will also attract those who are comfortable with uncertainty. In a highly dynamic situation, the courage to make choices (even if they might not be the right ones), and the skill to keep the OODA loop spinning are paramount.
A well-organized startup will have to run like a zodiac boat project. Startups rarely form around old ideas or long-discovered value niches. A lot of maneuvering will be necessary to uncover that motherlode. Any attempts to turn this zodiac boat into an aircraft carrier prematurely will dramatically reduce the probability of finding it. This is why ex-Googlers often struggle in startups: their culturally-instilled intuition will direct them to install nuclear reactors and rivet steel panels onto their boats – and in doing so, sink them.
Which brings me to engineering mastery. In my experience, there are two kinds of successful zodiac boat projects: ones run by people who aren’t that familiar with robust software engineering, and ones who have achieved enough software engineering mastery to know which practices can be broken and disregarded.
The first group of folks succeeded accidentally. The second – intentionally. This second group knows where to leave the right cheese holes in their project, and will do so consistently with magical results.
That’s what’s so tricky about forming zodiac boat projects. One can’t just put together a bunch of engineers into a small boat and let them loose. As with any elite special force, zodiac boat projects require a crew that is tightly knit, intrinsically motivated, and skilled to extreme.
Curiously, aircraft carrier-culture organizations can sometimes produce relatively high agility through what I call ergodic agility. The ergodic agility refers to the phenomenon where a multitude of projects are given room to start and fail, and over time, through the ergodic motion, find a new value niche. Here, the maneuverability is achieved through quantity and diversity of unchanging directions.
Like the infamous quote from Shrek, this process looks and feels like utter failure from inside of most of these teams, with the lucky winner experiencing the purest form of survivorship bias.
I am not sure if ergodic agility is more or less expensive for a large organization compared to cultivating an archipelago of zodiac boat teams and culture. One thing is certain: to thrive in an ever-changing world, any organization will need to find a way to have both aircraft carriers and zodiac boats in its fleet.
At its core, the process of layering resolves two counterposed forces. Both originate from the need for predictability in behavior. One from below, where the means are concrete, but the aims are abstract – and one from above, where the aims are concrete, but the means are abstract.
Each layer is a translation of an abstraction: as we go up in the stack of layers, the means become more abstract and the aims more concrete. At each end, we want to have predictability in what happens next, but the object of our concern is different. Lower layers want to ensure that the means are employed correctly. Higher layers want to ensure that the aims are fulfilled.
For example, a user who wants to press a button to place an order in the food-ordering app has a very concrete aim in mind for this button – they want to satisfy their hunger. The means of doing that are completely opaque to the user – how this will happen is entirely hidden by the veil of abstraction.
One layer below, the app has a somewhat more abstract aim (the user pressed a button), but the means are a bit more concrete: it needs to route the tap to the right handler which will then initiate the process of placing the order.
The aims are even less concrete at a lower layer. The button widget receives a tap and invokes an event handler that corresponds to it. Here, we are unaware of the user’s hunger. We don’t know why they want this button tapped, and nor do we care: we just need to ensure that the right sequence of things transpires when a tap event is received. The means are very concrete.
A reasonable question might be: why layer at all? Why not just connect the means and aims directly? This is where another interesting part of the story comes in. It appears that we humans have limits to the level of complexity of mental models we can reasonably contain in our minds. These limits are well-known to software engineers.
For a seasoned engineer, the pull toward layering emerges nearly simultaneously with the first lines of code written. It’s such a habit, they do it almost automatically. The experience that drives this habit is that of painful untangling of spaghetti after the code we wrote begins to resist change. This resistance, this unwillingness of cooperating with its own creator is not the fault of the code. It is the limit of the engineer’s mental capacity to hold the entirety of the software held in their minds.
When I talk about software with non-technical people, they are nearly always surprised about the amount of bugs any mature software contains. It seems paradoxical that older software has more bugs than the newer code. “What exactly are y’all doing there? Writing bugs?!” Yup. The mental model capacity needed to deeply grok a well-used, well-loved piece of software is typically way beyond that of any individual human.
So we come up with ways to break software into smaller chunks to allow us to compartmentalize their mental models, to specialize. And because of the way the forces of the aims and the means are facing each other, this process of chunking results in layering. Whether we want it or not, the layering will emerge in our code.
Putting it another way, layering is the artifact of the limits of human capacity to hold coherent mental models. If we imagine a software engineer with near-infinite mental model capacity, they could likely write well-functioning, relatively bug-free code using few (if any) layers of abstraction.
The converse is also true: lesser capacity to hold a mental model of traversing from the aims to the means will lead to software with more layers of abstraction.
By now, you probably know where I am going with this. Let’s see if we can apply these insights to the realm of large language models. What kind of layering will yield better results when we ask LLMs to write software for us?
It is my guess that the mental model-holding capacity of an LLM is roughly proportional to the size of this model’s context window. It is not the parametric memory that matters here. The parametric memory reflects an LLM’s ability to choose and apply various layers of abstraction. It is the context window that places a hard limit on what a model can and can not coherently perceive holistically.
Models with smaller context windows will have to rely on thinner layers and be more clever with the abstraction layers they choose. They would have to work harder and need more assistance from their human coworkers. Models with larger context windows would be able to get by with fewer layers.
How will the LLM-based software engineers compare to human counterparts? Here’s my intuition. LLMs will continue to be abysmally bad at understanding large code bases. There’s just way too many assumptions and tacit knowledge that lurks in those lines of code. We will likely see an industry-wide spirited attempt to solve this problem, and the solution will likely see thinning the abstraction layers within the code base to create safe, limited-scope lanes for synthetic software engineers to be effective in their work.
At the same time, LLMs will have a definite advantage over humans in learning the codebases that are well within their limits. Unlike humans, they will not get tired and are easily cloned. If I fine-tune a model on my codebase, all I need is the GPU/TPU capacity to scale it to a multitude of synthetic workers.
Putting these two together, I wonder if we’ll see the emergence of synthetic software engineering as a discipline. This discipline will encompass the best practices for the human software engineer to construct – and maintain – the scaffolding for the baklava of layers of abstraction populated by a hive of their synthetic kin.
This one is a bit out there, if only to connect some dots and shake loose new insights. Let’s get that distant look in our eyes and contemplate a possibility that may or may not transpire. Let’s all suppose that the upcoming AI winter is mild, and we settle into the next local maxima of technological progress, surrounded by helpful semi-autonomous agents, powered by large language models. What might that look like?
I am pretty sure I got the firmness of the performance asymptote wrong last May. The superlinear relationship between quality and cost is here to stay, and will shape a step-ladder-like differentiation of models based on their size. There will be larger models that produce high-quality results for a wide diversity of tasks – and are also expensive to run. There will be smaller models that are much, much cheaper, but also can only excel at a narrow task. We are likely to see attempts to establish a common scale for model complexity, rather than one model to rule them all.
Given that, we are likely to see more emphasis on the scaffolding that connects the models of varying sizes in addition to the models themselves. For instance, many startups and larger companies are already experimenting with the “inverted matryoshka” scaffolding, where a set of models is arranged so that the smaller, cheaper models are used more frequently for the simpler tasks and the largest models are only progressively reached for more complex (and hopefully, more rare) tasks.
Sure, there will be projects that try to hide that scaffolding under a “universal model”, which upon examination, will reveal a trenchcoat filled with the assortment of models, pretending to be one.
However, driven by the desire for agency, most will choose to rely on their access to this scaffolding to get better results. The scaffolding will be the secret sauce of success. The way we arrange the models – and how we choose and train the models for particular tasks – will continue to be the subject of intense experimentation and optimization, even when the pace of model innovation slows down.
This last sentence holds a startling realization. If we consider that each model is a “knowledge worker” of sorts, we can view the aforementioned scaffolding as an organization. If that’s the case, we can now imagine the process of creating and managing a collection of models as organization development. Except in this organization, the majority of workers are large language models.
Already, we see academic papers suggesting waterfall-like approaches to tasks, where multiple models (also known as agents) are lined in an assembly line of sorts, passing their output to the next one. I am also seeing experiments with parallel workstreams, converging together to be ranked. Each of the juncture points in these flows is a “virtual knowledge worker”. Perhaps not in the way Frederic Laloux intended, we are reinventing organizations.
It is quite possible (likely?) that organizations we will work in will include both human and non-human workers in them. These organizations will face the same challenges that any organization will face, and likely more new challenges that we haven’t even considered. There will be levels. Simple tasks performed by armies of lower-nomenclature model-powered workers (we’ll probably call them bots). More complex tasks performed by more expensive models. People will likely be supervising, directing, or tuning knowledge work. There might be an entirely new discipline of virtual organization development that emerges as a way of studying and finding more effective ways to conduct organizations that include model-based agents as part of their workforce.
This may not come to pass. However, what feels right in this picture is that humans will still be there. And because we are unpredictable, volatile humans, who come and go, who change our minds – there will always be a need to maintain a semblance of predictability around the business that owes the organization its existence. And because of that, the relatively more predictable and malleable workers might just serve as the organization development putty: keep adjusting the mixture of non-human workers in the organization to retain its strengths as people leave and join the organization – or change within it.
Perhaps in this future, we will ask not the question of whether or not AI will replace humans – but rather the question of how non-human knowledge workers can scaffold around us in a way that complements our gifts and gives us space to develop and grow.
Over the past couple of months, we’ve been working on a bunch of new things in the Breadboard project, mostly situated around developer ergonomics. I’ve mentioned creating AI recipes a bunch in the past, and it might be a good time to talk about the mental model of how such recipes are actually created.
❤️🔥 Hot reload
One of the Breadboard project design choices we’re leaning into is the “hot reload” pattern. “Hot reload” is fairly common in the modern developer UX, and we’d like to bring it into the realm of AI recipes. In this pattern, the developer sees not just the code they write, but also results of this code running, nearly instantaneously. This creates a lightning-fast iteration cycle, enabling the developer to quickly explore multiple choices and see which ones look/work better.
Most “hot reload” implementations call for two surfaces that are typically positioned side by side: one for writing the source code, and another for observing the results. In Breadboard today, the first one is typically an editor (I use VSCode) and the second one is our nascent Breadboard debugger.
As the name “hot reload” signifies, when I save the source code file in my editor, the debugger automatically reloads to reflect the recent changes.
The typical workflow I’ve settled into with Breadboard is that I start writing the board and get it to some point where it has enough to do at least something, I save the file and play with the board in the debugger. Playing with it both informs me whether I am on the right path and gives me ideas on what to do next.
I then act on this feedback, either fixing a problem that I am seeing, or progressing forth with one of the ideas that emerged through playing.
For my long-time readers: yes, we’ve baked the OODA loop right into Breadboard.
Overall, it’s a pretty fun experience. I get to see the board rising out of code by iteratively playing with it.
🪲 Debugger
To enable this fun, Paul Lewis has been doing the magician’s work bringing up the debugger. It’s very much a work in progress, though even what’s there now is already useful for board-making.
The main purpose of the debugger is to provide both the visualization of the AI recipe that is being developed and the process of it running. As I put it in chat, I love “seeing it run”: I get to see and understand what is happening during the run — as it happens! – and dig into every bit of detail.
There’s even a timeline that I can scrub through to better help me understand how events unfolded.
One thing that gives Breadboard its powers is that it’s built around a very flexible composition system. This means that my recipes may reach for other recipes during the run – sometimes a whole bunch of them. Reasoning about that can be rather challenging without help. As we all know, indirection is amazing until we have to spelunk the dependency chains.
To help alleviate this pain, the Breadboard debugger treats recipe invocations as the front-and-center concept in the UI. The timeline presents them as layers, similar to the layers in photo/video/sound editing tools. I can walk up and down the nested recipes or fold them away to reduce cognitive load.
There’s so much more work that we will be doing here in the coming weeks and my current description of the Breadboard debugger is likely to become obsolete very quickly. However, one thing will remain the same: the iteration speed is so fast that working with Breadboard is joyful.
🧸 Exploration through play
This leads me to the key point of what we’re trying to accomplish with the development cycle in Breadboard: exploring is fun and enjoyable when the iterations are fast and easily reversible.
This is something that is near and dear to my heart.
When the stakes in exploration are high, we tend to adopt a defensive approach to exploring: we prepare, we train, and brace ourselves when it is the time to venture out into the wilderness. Every such exploration is a risky bet that must be carefully weighted, and uncertainty reduced as much as possible.
When the stakes of exploration are low, we have a much more playful attitude. We poke and prod, we try this and that, we goof around. We end up going down the paths that we would have never imagined. We end up discovering things that couldn’t have been found by an anxious explorer.
It is the second kind of exploration that I would love to unlock with Breadboard. Even when learning Breadboard itself, I want our users to have the “just try it” attitude: maybe we don’t know how this or that node or kit works. Maybe we don’t have an answer to what parameters a recipe accepts. So we just try it and see what happens – and get reasonable answers and insights with each try.
If you’re excited about the ideas I wrote about here, please come join us. We’re looking for enthusiastic dance partners who dream of making the exploration of AI frontiers more accessible and enjoyable.
I recently had a really fun conversation with a colleague about “declarative vs. imperative” programming paradigms, and here’s a somewhat rambling riff that I captured here as a result.
When we make a distinction between “declarative” and “imperative” programming, we usually want to emphasize a certain kind of separation between the “what” and the “how”. The “what” is typically the intention of the developer, and the “how” is the various means of accomplishing the “what”.
For me, this realization came a while back, from a chat with Sebastian Markbåge in the early days of React, where he stated that React is declarative. I was completely disoriented, since to me, it was HTML and CSS that were declarative, and React was firmly in the imperative land.
It took a bit of flustering and a lot of Sebastian’s patience for me to grok that these terms aren’t not fixed. Rather, they are a matter of perspective. What might seem like “you’re in control of all the details” imperative from one vantage point will look completely declarative from another.
📏 The line between the “what” and the “how”
Instead of trying to puzzle out whether a given programming language, framework, or paradigm is declarative or imperative, it might be more helpful to identify the line that separates the “what” and the “how”.
For instance, in CSS, the “what” is the presentation of an HTML document (technically a DOM tree), and the “how” is the method by which this presentation is applied. In CSS, we declare what styling attributes we would like each document element to look like, and leave the job of applying these styles to the document in the capable hands of CSS.
Similarly, in React, we declare the structure of our components and their relationship to the state, while leaving the actual rendering of the application up to the framework.
Every abstraction layer brings some “declarativeness” with it, shifting the burden of having to think about some the implementation details from the shoulders of the developer into the layer.
If we look carefully, we should be able to see the line drawn between the “how” and the “what” in every abstraction layer.
In drawing this line, the creators of an abstraction layer – whether they are intentional about it or not – make a value judgment. They decide what is important and must remain in developer’s control, and what is not as important and could be abstracted away. I called this value judgment “an opinion” earlier in my writings.
One way to view such a value judgment is as a bet: it is difficult to know ahead of time whether or not the new abstraction layer will find success among developers. The degree of opinion underlines the risk that the bet entails. More opinionated abstraction layers make riskier bets than less opinionated ones.
If we measure reward in adoption and long-term usage, then the higher risk bets also promise higher reward: the degree of difference in opinion can serve as a strong differentiator and could prove vital to the popularity of the layer. In other words, if our layer isn’t that different from the layer below, then its perceived value isn’t that great to a developer.
Therein lies the ancient dynamic that underlies bets (or any value judgments, for that matter): when designing layers of abstraction, we are called to find that balance of being different enough, yet not too different from the layer below.
🪢 The rickety bridge of uncertainty
While looking for that balance, one of the most significant and crucial exercises that any framework, language, or programming paradigm will undertake is the one of value-trading with their potential developers.
This exercise can be described by one question: What is it that a developer needs to give up in order to unlock the full value of our framework?
Very commonly, it’s the degree of control. We ask our potential developers to relinquish access to some lower-layer capabilities, or perhaps some means to influence control flow.
Sometimes (and usually alongside with lesser control), it’s the initial investment of learning time to fully understand and gain full dexterity of wielding the layer’s opinion.
Whatever the case, there is typically a rickety bridge of uncertainty between the developer first hearing of our framework and their full-hearted adoption.
I once had the opportunity to explain CSS to an engineer who spent most of their career drawing pixels in C++, and they were mesmerized by the amount of machinery that styling the Web entails. If all you want to draw is a green box in the middle of the screen, CSS is a massively over-engineered beast. It is a long walk across unevenly placed planks to the point where the full value of this machinery even starts to make sense, value-wise. Even then, we’re constantly doubting ourselves: is this the right opinion? Could there be better ways to capture the same value?
This bridge of uncertainty is something that every opinionated layer has to cross. Once the network effects take root, the severity of the challenge diminishes significantly. We are socialized species, and the more people adopt the opinion that the abstraction layer espouses, the more normal it becomes – perhaps even becoming the default, for better or worse.
🧰 Bridging techniques
If we are to build abstraction layers, we are better off learning various ways to make the bridge more robust and short.
One technique that my colleague Paul Lewis shared with me is the classic “a-ha moment”: structure our introductions and materials in such a way that the potential value is clearly visible as early as possible. Trading is easier when we know what we’re gaining.
This may look like a killer demo that shows something that nobody else can do (or do easily). It may look like a tutorial that begins with a final product that just begs to be hacked on and looks fun to play with. It could also be a set of samples that elegantly solve problems that developers have.
Another technique is something that Bernhard Seefeld is actively experimenting with: intentionally designing the layer in such a way that feels familiar at first glance, but allows cranking up to the next level – incrementally. You can see this work (in progress 🚧) in the new syntax for Breadboard: it looks just like a typical JS code at first, rapidly ramping up to graph serialization, composition, and all the goodies that Breadboard has to offer.
I am guessing that upon reading these examples, you immediately thought of a few others. Bridging techniques may vary and the technique playbook will keep growing, but one thing that unites them all is that they aim to help developers justify the trade of their usual conveniences for the brave new world of the layer’s opinion.
Designing new layers is an adventure with the indeterminate outcome. We might be right about our value judgments, or we might be wrong. It could be that no matter how much we believe in our rightness, nobody joins to share our opinion with us. No technique will guarantee the outcome we wish for. And that’s what makes API design and developer experience work in general so fun for me.
Architecturally, Breadboard aspires to have an hourglass shape to its stack. As Bernhard Seefeld points out, this architecture is fairly common in compilers, and other NLP tools, so we borrowed it for Breadboard as well.
In this brief essay, I will use the Breadboard project to expand a bit on the ins and outs of the hourglass-shaped architecture.
At the waist of the hourglass, there’s a single entity, a common format or protocol. In Breadboard, it is a JSON-based format that we use to represent any AI recipe (I called them AI patterns earlier, but I like the word “recipe” better for its liveliness). When you look through the project, you’ll notice that all recipes are JSON files of the same format.
The actual syntax of the JSON file may change, but the meaning it captures will stay the same. This is one of the key tenets of designing an hourglass stack: despite any changes around it, the semantics of the waist layer must stay relatively constant.
The top part of the hourglass is occupied by the recipe producers, or “frontends” in the compiler lingo. Because they all output to the same common format, there can be a great variety of these. For example, we currently have two different syntaxes for writing AI recipes in TypeScript and JavaScript. One can imagine a designer tool that allows creating AI recipes visually.
Nothing stops someone from building a Python or Go or Kotlin or any other kind of frontend. As long as it generates the common format as its output, it’s part of the Breadboard hourglass stack.
The bottom part of the stack is where the recipe consumers live. The consumers, or “backends”, are typically runtimes: they take the recipe, expressed in the common format and run it. At this moment in Breadboard, there’s only a Javascript runtime that runs in both Node and Web environments. We hope that the number of runtimes expands. For instance, wouldn’t it be cool to load a Breadboard recipe within a colab? Or maybe run it in C++? Breadboard strives for all of these options to be feasible.
Runtimes aren’t the only kinds of backends. For instance, there may be an analysis backend, which studies the topography of the recipe and makes some judgments about its integrity or other kinds of properties. What sorts of inputs does this recipe take? What are its outputs? What are the runtime characteristics of this recipe?
Sometimes, it might be challenging to tell a backend apart from a frontend: an IDE may include both frontends (editor, compiler, etc.) and backends (runtime, debugger, etc.). However, it’s worth drawing this distinction at the system design stage.
The main benefit of an hourglass stack design is that it leaves a lot of room for experimentation and innovation at the edges of the stack, while providing enough gravitational pull to help the frontends and backends to stick together. Just like for any common language or protocol, the waist of the hourglass serves as a binding agreement between the otherwise diverse consumer and producer ideas. If this language or protocol is able to convey valuable information (which I believe we do with AI recipes in Breadboard), a network effect can emerge under the right conditions: each new producer or consumer creates combinatorial expansion of possibilities – and thus, opportunities for creating new value – within the stack.
It is far too early to tell whether we’ll be lucky enough to create these conditions for Breadboard, but I am certainly hopeful that the excitement around AI will serve as our tailwind.
The key risk for any hourglass stack is that it relies on interoperability: the idea that all consumers and producers interpret the common format in exactly the same way. Following the Hyrum’s Law, any ambiguity in the semantics of the format will eventually result in disagreements across the layers.
These disagreements are typically trailing indicators of the semantic ambiguities. By the time the bugs are identified and issues are filed, it is often too late to fix the underlying problems. Many languages committees spend eons fighting the early design mistakes of their predecessors.
As far as I know, the best way to mitigate this risk is two-fold. We must a) have enough experience in system design to notice and address semantic ambiguities early and b) have enough diversity of producers and consumers within the hourglass early in the game.
To be sure, a system design “spidey sense”, no matter how well-developed, and the ability to thoroughly exercise the stack early don’t offer 100% guarantees. Interoperability tends to be a long-term game. We can flatten the long tail of ambiguities, but we can’t entirely cut it off. Any hourglass-shaped architecture must be prepared to invest a bit of continuous effort into gardening its interoperability, slowly but surely shaving down the semantic ambiguities within the common format.
Here’s a riff on the “hourglass model” conversation I’ve had with Bernhard Seefeld a while back. I only recently connected it with my earlier mumblings about software layering, and here’s what came out.
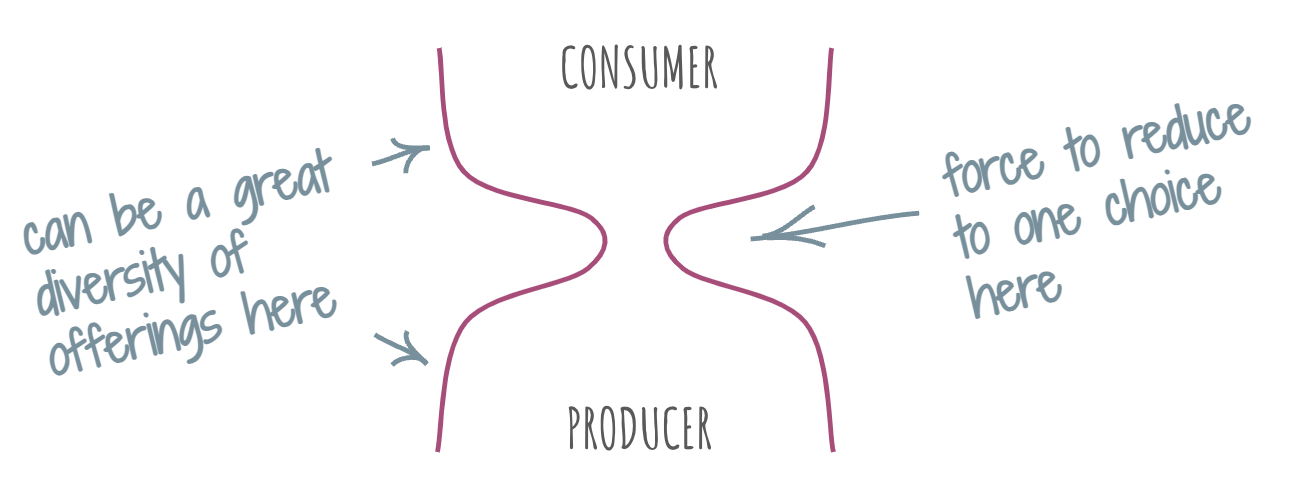
If a technology stack is arranged in such a way that there are consumers of value on one end of the stack and producers of it on the other, then at a certain scale, there emerges a force that encourages one middle layer of the stack – the waist – to be as thin as possible. There will be a distinct preference for lower diversity of offerings at that layer. IP, HTTP, and HTML are all great examples of this force’s effects.
I am going to call this force the “protocol force”, since the outcome of this force is usually a common protocol or format that is used for communicating across that layer.
To sketch out the mechanics behind the protocol force, the upper layers want to have access to more consumers, and those are only accessible through the lower layers. The lower layers want to get more producers, and only the upper layers can provide those. To get either, the layers have to go through the waist, and they all want to minimize the cost of bridging, of implementing all the permutations that enable consumers and producers to interact with each other. Put differently, everyone wants to spend as little as possible to reach as many consumers/producers as possible.
For instance, if we have multiple interaction protocols available in the waist layer, a growth spurt of an ecosystem of producers and consumers around this layer will trigger the “winner takes all” dynamics: a protocol that gets some critical mass of consumers (or producers) will reduce the appeal of using other protocols. As these other protocols will fall into disuse, the one that “won” will continue to gain new adopters – thus thinning the waist layer.
Interestingly, this protocol force may not manifest in the adjacent layers, even if they look like the connectors between the upper and the lower layers. As long as there’s one layer that is thin, the adjacent layers may enjoy high diversity of offerings.
A good example of this is the Web frameworks. There are always so many of them, right? Why is that? My explanation of this phenomenon, applying the reasoning above, is that they are protected from the effect of the protocol force by the Web Platform layer (the HTML/CSS/JS combo that we all love and enjoy) that sits right underneath them. This layer is incredibly thin: thanks to the set of circumstances and sheer designers’ luck, we only have one Web Platform.
Because of that, there can be a cornucopia of Web frameworks: as long as what they output is Web Platform-compatible, they won’t experience the pressure to agglomerate or race to the bottom.
The protocol force will be present in any layered stack that has producers and consumers as outer layers. One of the bridging layers will succumb to it. If we’re designing a layered system, we are better off preparing for this force to tap us on the shoulder and ask us to pick a layer to squish. Any resistance is futile. Might as well plan for it.
One of my favorite recent examples of such a design is the Protocol Buffers, a framework that Google uses internally to connect disparate pieces of functionality into one coherent whole. As long as a program speaks protos, it can mingle in Google-land. Whether intentionally or not, protocol buffers serve as the waist layer of Google infrastructure.
One of the key challenges of designing something as versatile as the Web Platform or protocol buffers is the fact that this layer will be the most used and, sadly. abused part of our stack. Once squished into a thin waist, this layer becomes the great enabler of our future – or the source of our doom. Its flexibility and capacity to convey the intentions of developers will be constantly tested and stretched and often broken. This is a sign of success and a good thing. As long as we’re prepared to invest into continuously improving and developing the waist of our stack, we can harness the protocol force to help us, rather than hinder.
Why do I find the problem of AI patterns and more generally, AI orchestration so interesting that I literally started building a framework for it? Why do we even need graphs and chains in this whole AI thing? My colleagues with a traditional software engineering background have been asking me this question a lot lately.
Put very briefly, at the height of the current AI spring that we’re experiencing, orchestration is a crucial tool for getting AI applications to the shipping point.
To elaborate, imagine that an idea for a software application takes a journey from inception to full realization through these two gates.
First, it needs to pass the “hey… this might just work” gate. Let’s call this gate the “Once” gate, since it’s exactly how many times we need to see our prototype work to get through it.
Then, it needs to pass through the “okay, this works reasonably consistently” gate. We’ll call it the “Mostly” gate to reflect the confidence we have in the prototype’s ability to work. It might be missing some features, lack in polish and underwhelm in performance benchmarks, but it is something we can give to a small group of trusted users to play with and not be completely embarrassed.
Beyond these two gates, there’s some shipping point, where the prototype – now a fully-fledged user experience – passes our bar for shipping quality and we finally release it to our users.
A mistake that many traditional software developers, their managers, and sponsors/investors make is that, when looking at AI-based applications, they presume the typical cadence of passing through these gates.
Let’s first sketch out this traditional software development cadence as a sequence below.
The “Once” gate plays a significant role, since it requires finding and coding up the first realization of the idea. In traditional software development, passing this gate means that there exists a kernel of a shipping product, albeit still in dire need of growing and nurturing.
The trip to the “Mostly” gate represents this process of maturing the prototype. It is typically less about ideation and mostly converging on the robust implementation of the idea. There may be some circuitous detours that await us, but more often than not, it’s about climbing the hill.
In traditional software development, this part of the journey is a matter of technical excellence and resilience. It requires discipline and often requires a certain kind of organizing skill. On more than one occasion, I’ve seen brilliant program managers brought in, who then help the team march toward their target with proper processes, burndown lists, and schedules. We grit our teeth and persevere, and are eventually rewarded with software that passes the shipping bar.
There’s still a lot of work to be done past that gate, like polish and further optimization. This is important work, but I will elide it from this story for brevity.
In AI applications, or at least mine and my friends/colleagues’ experiences with it, this story looks startlingly different. And definitely doesn’t fit into a neat sequential framing.
Passing the “Once” gate is often a matter of an evening project. Our colleagues wake up to a screencast of a thing that shouldn’t be possible, but somehow is. Everyone is thrilled and excited. Their traditional software developer instincts kick in: a joyful “let’s wrap this up and ship it!” is heard through the halls of the office.
Unfortunately, when we try to deviate even a little from the steps in the original screencast, we get perplexing and unsatisfying results. Uh oh.
We try boxing the squishy, weird nature of large language models into the production software constraints. We spend a lot of time playing with prompts, chaining them, tuning models, quantizing, chunking, augmenting – it all starts to feel like alchemy at some point. Spells, chants, and incantations. Maaaybe – maybe – we get to coax a model to do what we want more frequently.
One of my colleagues calls it the “70% problem” – no matter how much we try, we can’t seem to get past our application producing consistent results more than 70% of the time. Even by generous software quality standards, that’s not “Mostly”.
Getting to that next gate has little resemblance to the maturation process from traditional software development. Instead, it looks a lot more like the looping over and over back to “Once”, where we rework the original idea entirely and change nearly everything.
When working with AI applications, this capacity to rearrange everything and stay loose about the details of the thing we build, this design flexibility is what dramatically increases our chances of crossing to “Mostly” gate.
Teams that hinge their success on adhering to the demo they sold to pass through the “Once” gate are much more likely to never see the next gate. Teams that decide that they can just lay down some code and improve iteratively – as traditional software engineering practices would suggest – are the ones who will likely work themselves into a gnarly spaghetti corner. At least today, for many cases – no matter how exciting and tantalizing, the “70% problem” remains an impassable barrier. We are much better off relying on an orchestration framework to give us the space to change our approach and keep experimenting.
This is a temporary state and it is not a novel phenomenon in technological innovation. Every new cycle of innovation goes through this. Every hype cycle eventually leads to the plateau of productivity, where traditional software development rules.
However, we are not at that plateau yet. My intuition is that we’re still climbing the slope toward the peak of inflated expectations. In such an environment, most of us will run into the “70% problem” barrier head-first. So, if you’re planning to build with large language models, be prepared to change everything many times over. Choose a robust orchestration framework to make that possible.
I want to finally connect two threads of the story I’ve been slowly building across several posts. I’ve talked about the rise of makers. I’ve talked about the magicians. It’s time to bring them together and see how they relate to each other.
First, let’s paint the picture a little bit and set up the narrative.
The environment is ripe for disruption: there’s a new software capability and a nascent interface for it, and there’s a whole lot of commotion going on at all four layers of the stack. Everyone is seeing the potential, and is striving to glimpse the true shape of the opportunity, the one that brings the elusive product-market fit into clarity.
As I asserted before, there’s a brief moment when this opportunity is up for grabs, and the ground is more level than it’s ever been. Larger companies, despite having more resources, struggle to search for the coveted shape quickly due to the law of tightening aperture. Smaller startups and hobbyists can move a lot faster – albeit with high ergodic costs – and are able to cover more ground en masse. Add the combinatorial power of social networks and cozywebs, and it is significantly more likely that one of them will strike gold first.
For any larger player with strategic foresight, the name of the game is to “be there when it happens”. It might be tempting to try and out innovate the smaller players, but more often than not, that proves to be hubris.
Instead of trying to be the lucky person in the room, it is more effective to be the room that has the most exceptionally lucky person in it – and boost their luck as much as possible.
When the disruption does finally occur and the hockey stick of growth streaks upward, such a stance reduces the chances of counter positioning and improves the larger player’s ability to quickly learn from the said lucky person.
Put simply, during such times of rapid innovation, the task of attracting “exceptionally lucky people” to their developer ecosystems becomes dramatically more important for larger companies.
If the story indeed is playing out like so, then the notion of magicians is useful to identify those “exceptionally lucky people” – because luck compounds for those who explore the space in a way that magicians do.
But where do makers fit in? A good way to think of it as overlapping circles of two groups: developers and makers.
We’ll define the first circle as people who develop software, whether professionally or as a hobby. Developers, by definition, use developer surfaces: APIs, libraries, juts, tools, docs, and all those bits and bobs that go into making software.
The second circle is broader, because it includes folks who both develop and interact with software in a way that creates something they care about. Makers and developers obviously overlap. And since “maker” is a mindset, the boundary between makers and developers is porous: I could be a developer during the day and a maker at night. At the same time, not all developers are makers. Sometimes, it’s really just a job.
Makers who aren’t developers tend to gravitate toward becoming developers over time. My intuition is that the more engaged they become with the project, the more they find the need to make software, rather than just use it. However, the boundary that separates them from developers acts as a skill barrier. Becoming a developer can be a rather tough challenge, given the complexity of modern software.
Within these two circles, early adopters make up a small contingent that is weighted a bit toward makers. Based on how I defined maker traits earlier, it seems logical that early adopters will be primarily populated by them.
A tiny slice of the early adopter bubble on the diagram is magicians. They are more likely to be in the developer circle than not, since they typically have more expertise and skill to do their magic. However, there are likely some magicians hiding among non-developer makers, prevented by the learning curve barrier from letting their magic shine.
I hope this diagram acts as a navigational aid for you in your search for “exceptionally lucky” people – and I hope you make a room for them that feels inviting and fun to inhabit.