I think I have a slightly better way of describing a particular moment in a product’s life that I alluded to in Rock tumbler teams, Chances to get it right, and later, Build a thing to build the thing. I call this moment the “bootstrapping phase.” It very much applies to consumer-oriented products as well, but is especially pronounced – and viscerally felt – in the developer experience spaces.
I use the term “bootstrapping phase” to point at the period of time when our aspiring developer product is facing a tension of two forces. On one hand, we must start having actual users to provide the essential feedback loop that will guide us. On the other hand, the product itself isn’t yet good enough to actually help users.
The bootstrapping phase is all about navigating this tension in the most effective way. Move a little too much away from having the feedback loop, and we run the danger of building something that nobody wants. Go a little too hard on growing the user base, and we might prematurely conclude the story of the product entirely.
The trick about this phase is that all assumptions we might have made about the final shape of what we’re building are up in the air. They could be entirely wrong, based on our misunderstanding of the problem space, or overfit to our particular way of thinking. These assumptions must face the contact with reality, be tested – and necessarily, change.
The word “bootstrapping” in the name refers to this iterative process of evolving our assumptions in collaboration with a small group of users who are able and eager to engage.
Those of you hanging out in the Breadboard project heard me use the expression “unbaked cookies”: we would like to have you try the stuff we made, and we’re pretty sure it’s not yet cooked. Our cookies might have bits of crushed glass in them, and we don’t yet know if that cool new ingredient we added last night is actually edible. Yum.
At the bootstrapping phase of the project, the eagerness to eat unbaked cookies is a precious gift. I am in awe of the folks I know who have this mindset. For them, it’s a chance to play with something new and influence – often deeply – what the next iteration of the product will look like. On the receiving end, we get a wealth of insights they generate by trying – and gleefully failing – to use the product as intended.
For this process to work, we must show a complementary eagerness to change our assumptions. It is often disheartening to see our cool ideas be dismantled with a single click or a confused stare. Instead of falling prey to the temptation of filtering out these moments, we must use them as guiding signals – these are the bits that take us toward a better product.
The relationship between the bakers of unbaked cookies and cookie testers requires a lot of trust – and this can only be built over time. Both parties need to develop a sense of collaborative relationship that allows them to take risks, challenging each other. As disconcerting it may be, some insights generated might point at fundamental problems with the product – things that aren’t fixable without rethinking everything. While definitely a last resort, such rethinking must always be on the table. Bits of technology can be changed with some work. The mental models behind the product, once it ships to the broader audience are much, much more difficult to change.
Because of that, the typical UX studies aren’t a great fit for the bootstrapping phase of the project. We’re not looking for folks to react to the validity of mental models we imbued the nascent product with. We fully realize that some of them – likely many – are wrong. Instead, we need a collaborative, tight-feedback loop relationship with the potential users, who feel entrusted with steering the product direction through them chewing on not-yet baked cookies. They aren’t just trusted testers of the product. They aren’t just evaluators of it. They are full participants in its development, representing the users.
I want to finally connect two threads of the story I’ve been slowly building across several posts. I’ve talked about the rise of makers. I’ve talked about the magicians. It’s time to bring them together and see how they relate to each other.
First, let’s paint the picture a little bit and set up the narrative.
The environment is ripe for disruption: there’s a new software capability and a nascent interface for it, and there’s a whole lot of commotion going on at all four layers of the stack. Everyone is seeing the potential, and is striving to glimpse the true shape of the opportunity, the one that brings the elusive product-market fit into clarity.
As I asserted before, there’s a brief moment when this opportunity is up for grabs, and the ground is more level than it’s ever been. Larger companies, despite having more resources, struggle to search for the coveted shape quickly due to the law of tightening aperture. Smaller startups and hobbyists can move a lot faster – albeit with high ergodic costs – and are able to cover more ground en masse. Add the combinatorial power of social networks and cozywebs, and it is significantly more likely that one of them will strike gold first.
For any larger player with strategic foresight, the name of the game is to “be there when it happens”. It might be tempting to try and out innovate the smaller players, but more often than not, that proves to be hubris.
Instead of trying to be the lucky person in the room, it is more effective to be the room that has the most exceptionally lucky person in it – and boost their luck as much as possible.
When the disruption does finally occur and the hockey stick of growth streaks upward, such a stance reduces the chances of counter positioning and improves the larger player’s ability to quickly learn from the said lucky person.
Put simply, during such times of rapid innovation, the task of attracting “exceptionally lucky people” to their developer ecosystems becomes dramatically more important for larger companies.
If the story indeed is playing out like so, then the notion of magicians is useful to identify those “exceptionally lucky people” – because luck compounds for those who explore the space in a way that magicians do.
But where do makers fit in? A good way to think of it as overlapping circles of two groups: developers and makers.
We’ll define the first circle as people who develop software, whether professionally or as a hobby. Developers, by definition, use developer surfaces: APIs, libraries, juts, tools, docs, and all those bits and bobs that go into making software.
The second circle is broader, because it includes folks who both develop and interact with software in a way that creates something they care about. Makers and developers obviously overlap. And since “maker” is a mindset, the boundary between makers and developers is porous: I could be a developer during the day and a maker at night. At the same time, not all developers are makers. Sometimes, it’s really just a job.
Makers who aren’t developers tend to gravitate toward becoming developers over time. My intuition is that the more engaged they become with the project, the more they find the need to make software, rather than just use it. However, the boundary that separates them from developers acts as a skill barrier. Becoming a developer can be a rather tough challenge, given the complexity of modern software.
Within these two circles, early adopters make up a small contingent that is weighted a bit toward makers. Based on how I defined maker traits earlier, it seems logical that early adopters will be primarily populated by them.
A tiny slice of the early adopter bubble on the diagram is magicians. They are more likely to be in the developer circle than not, since they typically have more expertise and skill to do their magic. However, there are likely some magicians hiding among non-developer makers, prevented by the learning curve barrier from letting their magic shine.
I hope this diagram acts as a navigational aid for you in your search for “exceptionally lucky” people – and I hope you make a room for them that feels inviting and fun to inhabit.
Technological innovation can be viewed as a network of miracles: breakthroughs that make possible something that wasn’t impossible before. Some miracles are major and others are minor.
It is the job of a technology strategist to identify miracles that will happen or will need to happen to make forward progress on the idea they have in mind. Miracles are fickle. Their appearance is not guaranteed. Something that looks like it’s just within reach can continue to stay that way for decades. Betting on a miracle is never safe – otherwise, they won’t be called miracles.
It is in this context that the tension between two forces arises.
On one side of this tension, there’s a desire to increase the likelihood of making forward progress. It usually shows up as wanting to pick the safer, more predictable next steps, and reduce the impact of the miracle not happening.
On the other side, there’s the wish to move forward faster. This is where we see the impatience and the urge to dream big, and reach for the stars – to go all in on bringing the miracle forth.
Both extremes lead to unproductive outcomes. Making safe bets means not being different from the rest of contenders, and being different is the name of the game in technological innovation. At the same time, the unhealthy disregard for the impossible is a great recipe for losing everything and gaining nothing.
To resolve this tension, I’ve learned to apply the “one miracle at a time” principle. The gist of this principle is that we pick one challenging part of the idea we’d like to realize and find ways to de-risk everything else. We minimize the number of miracles necessary for success of the one we care about.
This doesn’t mean we give up on the larger vision. A good way to think about it as finding the first stepping stone to jump to. Sometimes it’s helpful to imagine lining up all the miracles into a series of steppings stones. Which one will we start with?
Applying this principle to practice might look like this.
1️⃣ Start with the inventory of miracles. Have a rigorous miracle count conversation. What’s loosely easy and what’s difficult? How hard are the difficult bits? Which ones feel like miracles?
2️⃣ With the miracles rounded up, find the ones that are important. There will always be the miracles that feel more like dependencies compared to those at the core of the vision. Consider taking those miracles off the table. Apply this rule of thumb: the stronger your conviction around the vision, the less you should care about the dependency miracles.
3️⃣ Pick one. Ensure that everyone has the same one miracle in mind. Very often, especially in teams that are running ahead of the pack, we will find a large diversity of what peeps are passionate about. This diversity is great for ideation, but when we’re choosing the miracle, it can be counter-productive.
A common trend, especially among organizational cultures biased toward being agreeable, is that there’s a whole portfolio of pet miracles being brought along with the chosen one: everyone says “okay, let’s focus on that one” and thinks “… and mine, too”.
Choosing the next miracle is a convergent process. It requires difficult and honest conversations. In my experience, this is the hardest step.
Don’t be surprised if the chosen miracle is a minor dependency. This likely means that the vision is vague and needs further refinement – and few ways are better to do so than trying to start at the edges of the problem.
4️⃣ Once the miracle is picked, work to reduce uncertainty everywhere else. Formulate ideas in a way that are complementary to what is currently possible. Replace all those dependency miracles with withered tech – something that’s well-established and known to be reliable. Align with projects and priorities that are already on everyone’s mind.
There will be worries and well-argued points about how choosing today’s technologies to build tomorrow’s is fraught with peril. They will be very tempting. I’ve gotten snared by them many times. I also found that the most productive way is to embrace the paradox. Accept these arguments as true – and yet, recognize that each new miracle cuts down the odds of our work mattering when tomorrow finally arrives.
With miracles, there’s always a coin toss somewhere. Some things we thought were certain and simple prove otherwise. And things that we decided weren’t worth paying attention boomerang at our backs. By picking one miracle at a time, we can reduce the total surface of uncertainty and be principled about where we focus our attention.
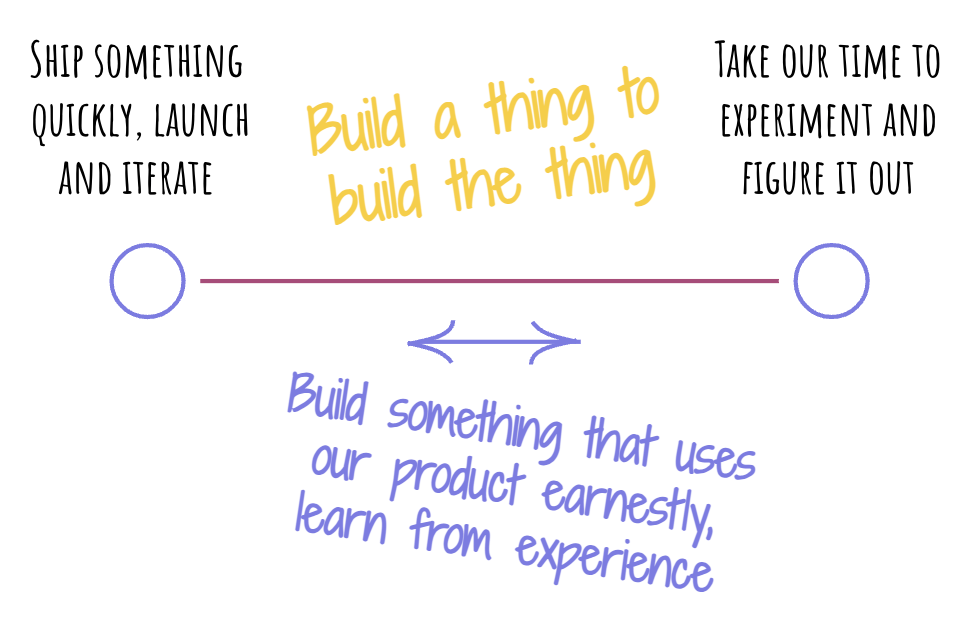
When building new products, there’s always a weird tension between making something “real” and production-ready, and spending a bit of time just experimenting with all of the various ideas of what this “real” might look like.
This tension is less noticeable when we actually know what we want to build. If I am building a new Web rendering engine, I literally have all the specs – and a few well-established implementations for reference. However, when the actual product is a bit of an unknown, the tension starts to surge.
There are typically two forces that create this tension. First, therse’s the desire to ship expeditiously and engage the customers. This might come from the intention to maximize our chances to get it right, but also could just be a business necessity.
Then, there’s another force – the desire to deliver something that truly resonates with the customers. It’s bizarre how the underlying animating intention could be the same “let’s get it right”, but the approach is different: instead of jumping in as soon as possible, we try to first figure out what “right” looks like.
My intuition is that the two varying approaches come from different evaluations of the “chances budget”: how many chances does this particular idea have before we blew it? Folks who see a large chance budget will veer toward “let’s just ship something and iterate (or survive/get promoted, etc)”. Folks who see only a handful of chances in the budget will tend to “let’s first get our ducks in a row”.
Depending on the organization, there will be a pull toward one extreme or another: and sometimes a soup of both at the same time. There might be peeps jumping to ship whatever remotely looks like a feature and spend marketing dollars on boosting its visibility. There might also be people trying to carefully orchestrate large-scale “spherical cow” ecosystems that can only practically exist in a caffeine-induced slide deck.
📐 The Principle
In my experience, the trick to resolve this tension is the practice I call “build a thing to build the thing”. It’s a pretty simple trick, please don’t get too excited. The hard part is mostly in knowing how to apply it.
When we decide to “build a thing to build the thing”, we agree to focus first on building something that is immediately adjacent to what we actually want to build. In the developer experience field, this adjacency most commonly looks like this: “Let’s build something useful with our product, and see what we learn from it”.
If we’re building a new library or framework, let’s build something that uses it – so that we learn how to improve our library or framework. Build a thing to build the thing.
“Earnest effort” is an important ingredient. If this is just some half-hearted dabbling to check the box, the trick will not work.
Close to a decade ago, when I was working on the Chrome Web Platform team, we wanted to get a better sense of whether or not the APIs and primitives we’re shipping are actually helping developers make better mobile Web applications.
So a few of us locked ourselves in a room and spent a few weeks actually trying to build a clone of a well-known mobile app as a Web app, powered by the latest and greatest bits that we were shipping or about to ship. Our hypothesis was a negative proof: if we – the people who actually build the platform bits – can’t do it, then nobody can.
We also adopted the “live as our customer” posture and used only the tools that were available outside of Google.
Every week, we wrote up a report of what we learned. Where the friction was, where the seemingly easy tasks turned into albatrosses. Where primitives and APIs that we thought were useful actually weren’t.
We failed gloriously. I remember showing the Web app to our VP and the first load taking hundreds of seconds on a reasonably crappy phone. We tried hard. We rummaged in all the bags of tricks. We profiled JS. We profiled C++. We messed with V8 and Chromium code trying to make it less slow. In one particularly unwise moment, I wrote code to construct DOM with C++. At the end of the adventure, we had an incontrovertible proof: if we wanted for mobile Web apps to be on par with their native equivalents, we had to do something different as a team.
This exercise served as a shift for how I and my colleagues thought about what’s important (and not important). It triggered a change in priorities for the larger organization. I’ll spare the gory details of how it all went down. Suffice to say, a big chunk of the current narrative about Web performance was shaped by the insights we gained from our adventure.
Sometimes, building a thing to build the thing is clarifying like that. Sometimes, it just creates more questions. Whatever the outcome, there will be precious insights, waiting for us to be harvested.
💔 The hard part
The greatest challenge of adhering to the “build a thing to build the thing” principle is in our own ability to be honest with ourselves.
Here are some failure cases that I’ve seen. Use them as tripwires if you decide to apply this principle.
1️⃣ The DevRel trap. During the exercise, the people who are building on top of the product are different from those who are building the product. For instance, a contractor or a DevRel team is building an app with the library that the engineering team built. This insidious pattern is so widespread that it’s even considered a best practice. In my experience, it is anything but. It feels so obvious: of course DevRel folks are the best people to do this project!
However, most of the valuable insights will fall into the crack between the DevRel and the engineering team. Glorious failures will not trigger reevaluation of priorities, but rather shrugs and side glances at the DevRel team: “Well, maybe they’re not as good as we thought they were”.
2️⃣ Forgetting the thing. We get so engrossed in the exercise that we forget which thing we’re actually building. This most commonly happens when the main product is vague and ill-defined, and the adjacent thing feels a lot more concrete and graspable.
The chain of events that leads to this failure case usually looks like this:
Step 1: We want to build <foo>.
Step 2: <foo> is entirely ill-defined. We have no clue how to build it.
Step 3: We decide to start with <bar>, which is a thing that could be built with <foo>.
Step 4: A few weeks/months later… We’re building <bar>. Nobody remembers <foo>.
There is nothing wrong with a product pivot. Just make sure it’s done intentionally.
3️⃣ The confirmation demo. Like confirmation bias, confirmation demos only show the good parts of your products. These “things built to build things” aren’t made to challenge the assumptions or draw insights. They are carefully crafted potemkin villages whose entire purpose is to avoid novel insights to be drawn. These things will change no minds.
Don’t get me wrong. Demos are important. However, they are in an entirely different universe from applying the “build a thing to build the thing” principle.
Anytime the ambiguity of the path forward is high, and it is not quite clear what we’re building, it might be worth having at least one “a thing to build the thing” exercise in progress, and that the insights from it are collected diligently to aid with navigating complexity.
This principle is something that feels very intuitive at first blush, but in my experience, is rather challenging to adhere to, especially as a team.
I will present this principle as resolving a tension between two forces that are very familiar to me in the realm of developer experience. I am pretty sure that these forces are still present in any other product development, albeit they may have different specific traits.
When building developer products for others, we often have a situation where the development environments that our customers have are different from ours.
They may use different stacks, build systems, or apply different processes from ours. Conversely, we may have our special tools that we’re used to and our particular practices that we employ to be more productive.
This difference forms the basis for the tension. Clearly, to ship a product that my customer loves and is willing to adopt means that I need to understand their environment. I need to know deeply the problems that they are facing every day: what is difficult? What is easy? Where can I help?
At the same time, I have my own environment that I am very comfortable in, honed by years of practice and incremental improvements. This is the environment that works best for me. This is the environment that I understand deeply, with all its quirks and idiosyncrasies.
The platonic ideal here is that I have it both ways: I deeply understand both environments, am able to hold both of them in mind, and develop for one while working in another. If you can do this, kudos to you. But more than likely, there’s a bit of self-delusion going on. Based on my experience, this is simply not possible.
Instead, we subconsciously lean toward problems that we encounter in our environments, and tend to be blind toward the ones that our potential customers have. When we ship a thing, it looks like an alien artifact. It appears to solve problems that our customers don’t have, or try to solve their problems in weird, unworkable ways.
Imagine you’re an alien who was hired to be a chef. You’re asked to cook for humans. You can’t eat human food, and some of it looks revolting, honestly. Fried eggs. Blegh. How likely are you to cook something that humans will like?
This tension grows stronger if the difference between the environments is large. Putting it very bluntly: if our developer experience is so different that it feels like an island, we can’t build developer experience products that others will love — or even understand.
To resolve this tension, we must live as our customers. We must strive to shift to as close to the same environment as they have. If our customers use Github as their primary tool, we’d better use Github, as well. If the customers we target mostly use Fortran (bless them!), well then we must learn and adopt it as well.
Applying this principle is usually super-uncomfortable at first. Nobody wants to abandon their well-worn saddle. The new saddle will cause cramps and sore muscles for a while. Expect a lot of pushback and well-reasoned arguments to return to the trusted old saddle. “This bug tracker sucks! I can’t even use keyboard shortcuts to navigate between issues! Our is so much better!” “OMG, this build system is arcane! What is all this XML stuff?! I thought we were in the 21st century?!”
There’s a kind of test that is built into this struggle. We signed up to build for these customers. Do we actually want to do that?
If the answer is still “yes”, we will find that we will be better off in the long term. We will have a much deeper sense of what our customers need, and where the pain points are. We will be able to spot them early and build things that they want to use.
I’ve been playing with various software development configurations that might enable rapid experimentation, and landed on this particular one. I am pretty sure there are even more effective ways, and I can’t wait to learn from you about them. This is what I have so far.
A quick disclaimer: this is not yet another “how to set up a repo” tutorial. It’s mostly a capture of my learnings. I will refer to a couple of such tutorials, though.
To set things up. I was looking for a way to enable a small-ish team to enable development of rapid prototypes. That is, write something, see if it does what we need, test the waters, learn like crazy, and break no sweat if it doesn’t.
🧫 Ecosystem
The first question on my mind was that of the developer ecosystem. To unlock fertile learning through testing the waters, prototypes need to ship. They do not have to ship as polished products with firm SLAs, but they do need to reach some users who would be willing to mess with the prototypes, react to them, and provide feedback. To maximize the chances of serendipitous feedback, we must play in the most populous ecosystems of folks who like to mess with unpolished stuff. When choosing a place to learn, pick the rowdiest bazaar.
This requirement narrowed down the possible environments quite a bit. Looking at Stack Overflow survey results, the two ecosystems stood out as by far the most legible for the title: Javascript developers and Python developers. They form the fat head of the developer environment power curve. These are the places to play.
I then spent a bunch of time messing with both environments, and ended up deciding on the Javascript ecosystem. There were several reasons for that, not all of them entirely objective. Roughly, it all came down to two factors:
Javascript runs both in the browser and on the server, and the surprising amount of code and infrastructure that can be shared between the two allows for fewer jumping through hoops to make things go;
The overall state of the scaffolding and tooling in the Javascript ecosystem seems to be a touch less messy than that of Python, with Python still overcoming some of the legacy warts around package publishing, environment isolation, transition to python3, and addition of types. At least for me, I found that I end up fighting Python more often than fighting Javascript.
🧰 Toolchain
After picking the environment, I wasted a bunch of time resisting TypeScript. As a Javascript old-timer and a known build step grump, I really didn’t want to like it. But after getting over my hang ups, I must admit: TypeScript is basically the best thing that could ever happen to unlock rapid prototyping. As long as I know where the layer gaps are (hint: the missing runtime type support), it’s basically the perfect tool for the job. Especially with the way it is integrated into VSCode, TypeScript hovers at just the right altitude to help me write the code quickly and have high confidence in this code working on the first run.
Which brings me to the next increment in my journey. If we choose TypeScript, we must go with VSCode as the development surface. I am sure there are other cool editors out there (I hear you, vim/emacs fans!), but if we’re looking for something that fits TypeScript like a glove, there is simply no substitute. Combined with eslint and prettier, the VSCode support for TypeScript makes development an enjoyable experience.
So… Node, Web, TypeScript, VSCode. These are the choices that came out of my exploration. I briefly played with the various Node package managers, and concluded that npm is likely the thing to stick with. I love the idea behind pnpm and yarn is super-fun, but at least for me, I decided to go with what comes in the box with Node. Deno is cool, too – but as a newcomer, it simply doesn’t meet the “rowdiest bazaar” bar.
The choices made so far define the basic shape of the prototypes we will develop and the sketch of the development flow. The prototypes will be either shipped as Web apps or libraries/tools as npm packages. Every prototype will start as an npm package. It might have server-only code, client-only code, or a mix of both. Prototypes that look like tools and libraries will be published on npm.
#️⃣ Runtime versions and settings
I invested a bit of time deciding on versions and settings of TypeScript and Node. One key guiding principle I chose was “as close to the metal as possible”. TypeScript compiler is quite versatile and it can output to a variety of targets to satisfy the needs of even the most bizarre deployments. Given that we’re prototyping and writing new code, we don’t need to concern ourselves with the full breadth of deployment possibilities – and we certainly can be choosy about the version of the browser we expect to present our experiments.
With this leeway and the recognition that TypeScript is mostly an implementation of ECMAScript (the standard behind Javascript) plus type annotations, we can configure the TypeScript compiler to mostly remove type annotations.
For Node, I chose to go with v18.16, primarily because this is the version that introduced the real fetch implementation, which matches what modern Web browsers ship.
So, if we have Node 18 and the config of the TypeScript below, we should minimize the amount of new code introduced by the TypeScript compiler and maximize the client/server code compatibility.
As an aside, there was a fun rabbit hole of a layer gap into which I fell while exploring this space. Turns out, Node TypeScript type annotations don’t have the declarations for the fetch implementation. So I ended up doing this funky thing with adding the “DOM” library to the TypeScript config. This worked better than I expected. As long as we remember that a) TypeScript types are not seen by the actual Javascript runtime and b) most of the actual DOM objects aren’t available in Node, one can get away with a lot of fun hacks. For example, we can run unit tests for client-side code on the server!
🏠 Repository configuration and layout
With versions and runtime configs squared away, I proceeded to fiddle with configuring the repository itself. I first started with the “let a thousand tiny repos bloom” idea, but then quickly shifted toward the Node monorepo. This choice might seem weird given the whole rapid prototyping emphasis. The big realization for me was that we want to encourage our prototypes to mingle: we want them to easily reuse each other’s bits. It is out of those dependencies that interesting insights emerge. We might spot a library or a tool in a chunk of code that every other prototype seems to rely on. We might recognize patterns that change how we think about the boundaries around prototypes and would need space to reshape them. With all prototypes being individual packages, the friction of dependency tracking will simply prevent that.
There are multitudes of ways in which one could bring up a TypeScript monorepo. I really liked this guide, or this setup that relies exclusively on the TypeScript compiler to track dependencies. Ultimately, I realized that I prefer to use separate build tools that track the dependency build graph, and invoke the compiler to do their bidding. This is the setup that Vercel’s Turborepo folks advocate, and this is the one I ended up choosing.
Any Node monorepo will loosely have this format: there will be a bunch of config files and other goop in the root of the repository, and then there will be a directory or two (usually called “packages” or “apps”) that contains directories for the individual packages.
My intuition is that to facilitate rapid prototyping, we need a convention that reflects the state of any package in the monorepo. For example, we could have two package-holding directories, one for “seeds” and one for “core”. In the “seeds” directory, we place packages that are early prototypes that we’re just playing around with. Once a package acquires dependencies and becomes useful for other prototypes, we graduate to the “core” directory.
Another useful convention when working with Node monorepos is that the npm package names are all scoped under the same npm organization and the name of that organization matches the name of the repo.
So for example, if our monorepo is named “awesome-crew-prototypes”, all packages are published under the “@awesome-crew-prototypes” npm organization. For example, a prototype for a library that does URL parsing will be published as “@awesome-crew-prototypes/url-parser”. This way, the fact that the “url-parser” is part of the “awesome-crew-prototypes” monorepo is reflected in its name.
🚀 Team practices
As the final challenge, I worked out the best practices for the team that might be working in this repository. This section is the least well-formed, since typically, the practices emerge organically from collaborating together and depend quite a bit on the mix of the people on the team.
Having said that, the following rules of thumb felt right right as the foundation for the practices:
Mingle – seek to reuse other packages that we build, but don’t panic if that doesn’t work out. Think of reuse as very, very early indicators of a package usefulness.
Keep the rewrite count high – don’t sweat facing the possibility of rewriting the code we’re writing multiple times.
Duct tape and popsicle sticks – since we’re likely going to rewrite it, what lands does not need to be perfect or even all that great, as long as it gets the job done.
Ship many small things – rather than aiming for a definite product with a “wow” release moment, look to ship tiny tools and libraries that are actually helpful.
Armed with all of these, a team that is eager to experiment should be able to run forward quickly and explore the problem space that they’ve chosen for themselves, and have fun along the way. Who knows, maybe I’ll actually set up one of these myself one day. And if I do, I’ll let you know how it goes.
I also quickly put together a template for the environment that I described in this post. It probably has bugs, but should give you a more concrete idea of the actual setup.
There seems to be some layering rhythm to how software capabilities are harnessed to become applications. Every new technology tends to grow these four layers: Capabilities, Interfaces, Frameworks, and Applications.
There does not seem to be a way of skipping or short-cutting around this process. The four layers grow with or without us. We either develop these layers ourselves or they appear without our help. Understanding this rhythm and the cadence of layer emergence could be the difference between flopping around in bewilderment and growing a durable successful business. Here are the beats.
⚡ Capabilities
Every new technological capability usually spends a bit of time in a purgatory of sorts, waiting for its power to become accessible. It needs to traverse the crevasse of understanding: move from being grokable by only a handful of those who built it to some larger audience. Many technologies dwell in this space for a while, trapped in the minds of inventors or in the hallways of laboratories. I might be stating the obvious here: the process of inventing something is not enough for it to be adopted.
I will use large language models as the first example in this story, but if you look closely, most technological advances follow this same rhythm. The transformer paper and the general capability for building models has been around for a while, but until last year, it was mostly contained to the few folks who needed to understand the subject matter deeply.
🔌 Interfaces
The breakthrough usually comes in the form of a new layer that emerges on top of the capability: the Interfaces layer. This is typically what we see as the beginning of the technology adoption growth curve. The Interfaces layer can be literally the API for the technology or any other form of simplifying contract that enables more people to start using the technology.
The Interfaces layer serves as the democratizer of the Capabilities layer: what was previously only accessible to the select few – be that due to the complex nature of the technology, capital investment costs, or some other barrier – is now accessible to a much larger group. This new audience is likely still fractionally small compared to all the world’s population, but it must be numerous enough for the tinkering dynamic to emerge.
This tinkering dynamic is key to the success of the technology. Tinkerers aren’t super-familiar with how the technology works. They don’t have any of the deep knowledge or awareness of its limits. This gives them a tremendous advantage over the inventors of the technology – they aren’t trapped by the preconceived notions of what this technology is about. Tinkers tinker. Operating at the Interfaces layer, they just try to apply the tech in this way and that and see what happens.
Many research and development organizations make a crucial mistake by presuming that tinkering is something that a small group of experts can do. This usually backfires, because for this phase of the process to play out successfully, we need two ingredients: 1) folks who have their own ideas about what they might do with the capabilities and 2) a large enough quantity of these folks to actually start introducing surprising new possibilities.
Because of this element of surprise, tinkering is a fundamentally unpredictable activity. This is why R&D teams tend to not engage in it. Especially in cases when the societal impact of technology is unclear, there could be a lot of downside hidden in this step.
In the case of large language models, OpenAI and StabilityAI were the ones who decided that this risk was worth it. By providing a simple API to its models, OpenAI significantly lowered the barrier to accessing the LLM capabilities. Similarly, by making their Stable Diffusion model easily accessible, StabilityAI ushered a new era of tinkering with multimodal models. They were the first to offer the large language models Interfaces layer.
Because it’s born to facilitate the tinkering dynamic, the Interfaces layer tends to be opinionated in a very specific way. It is concerned with reducing the burden of barriers to entry. Just like any layer, it does so by eliding details: to simplify, some knobs and sliders become no longer accessible to the consumer of the interface.
If the usage of the Interfaces layer starts to grow, this indicates that the underlying Capabilities layer appears to have some inherent value, and there is a desire to capture as much of this value as possible.
🔋Frameworks
This is the point at which a new layer begins to show up. This third layer, the Frameworks, focuses on utility. This layer asks: how might we utilize underlying the Interfaces layer in more effective ways, and make it even more accessible to an even broader audience?
Utility might mean different things in different situations: in some, the value of rapidly producing something that works is the most important thing. In others, it is the overall performance or reliability that matters most. Most often, it’s some mix of both and other factors.
Whatever it is, the search for maximizing utility results in development of frameworks, libraries, tools, and services that consume the Interfaces layer. Because there are many definitions of utility and many possible ways to achieve it, the Frameworks layer tends to be the most opinionated of the stack.
In my experience, the diversity of opinion introduced in the Frameworks layer depends on two factors: the inherent value of the capability and the own opinion of the Interfaces layer.
The first factor is fairly straightforward: the more valuable the capability, the more likely there will be a wealth of opinions that will grow in the Framework layer.
The second factor is more nuanced. When the Interfaces layer is introduced, its authors build it by applying their own mental model of how the capability will be used via their interface. Since there aren’t actual users of the layer yet, it is at best a bunch of guesses. Then, the process of tinkering puts these guesses to the test. Surprising new uses are discovered, and the broadly adopted mental models of the consumers of the interface usually differ from the original guesses.
This difference becomes the opinion of the Interfaces layer. The larger this difference, the more effort the Frameworks layer will have to put into compensating for this difference – and thus, create more opportunities for even more diversity of opinion.
An illustration for how this plays out is the abundance of the Web frameworks. Since the Web browser started out as the document-viewing application, it still has all of those early guesses firmly entrenched. Indeed, the main API for web development is called the Document Object Model. We all have moved on from this notion, asking our browsers to help us conduct business, entertain us, and work with us in many more ways than the original designers of this API envisioned. Hence, the never-ending stream of new Web frameworks, each trying yet another way to close this mental model gap.
It is also important to call out a paradox that develops as a result of the interaction between the Frameworks and the Interfaces layer. The Frameworks layer appears to simultaneously apply two conflicting pressures to the Interfaces layer below: to change and to stay the same.
On one hand, it is very tempting for the Interfaces layer maintainers to change it, now that their initial guesses were tested. And indeed, when talking to the Frameworks layers developers, the Interfaces layer maintainers will often hear requests for change.
At the same time, changing means breaking the existing contract, which creates all kinds of trouble for the Frameworks layer – these kinds of changes are usually a lot of work (see my deprecation two-step write-up from a while back) and take a long time.
The typical state for a viable Interfaces layer is that it is mired in a slow slog of constant change whose pace feels glacial from the outside. Once the Frameworks layer emerges, the API layer becomes increasingly more challenging to evolve. For those of you currently in this slog, wear it as a badge of honor: it is a strong signal that you’ve made something incredibly successful.
The Frameworks layer becomes the de-facto place where the best practices and patterns of applying the capability are developed and stored. This is why it is only after a decent Frameworks layer appears do we start seeing robust Applications actually utilizing the capability at the bottom of the stack.
📱Applications
The Applications layer tops our four-stack of layers. This layer is where the technology finally faces its users – the consumers of the technological capability. These consumers might be the end users who aren’t at all technology-savvy, or they could be just another group of developers who are relieved to not have to think about how our particular bit of technology works on the inside.
The pressure toward maximizing utility develops at this layer. Consumer-grade software is serious business, and it often takes all available capacity to just stay in the game. While introducing new capabilities could be an appealing method to expand this business, at this layer, we seek the most efficient way possible to do so. The whole reason the Frameworks layer exists is to unlock this efficiency – and to further scale the availability of the technology.
This highlights another common pitfall of a research organization is to try to ram a brand new capability right into an application, without thinking about the Interfaces and Frameworks layers between them. This usually looks like a collaboration between the team that builds at the Capabilities layer and the team that builds at the Application layer. It is usually a sordid mess. Even if the collaboration nominally succeeds, neither participant is happy in the end. The Capability layer folks feel like they’ve got the most narrow and unimaginative implementation of their big idea. The Application folks are upset because now they have a weird one-off turd in their codebase.
👏 All together now
Getting technology adopted requires cultivating all four layers. To connect Capabilities to Applications, we first need the Interfaces layer that undergoes a significant amount of tinkering, with a non-trivial amount of use case exploration that helps map out the potential space of solutions that the new technology can actually solve. Then, we need the Frameworks layer to capture and embody the practices and patterns that trace the shortest paths across the explored space.
This is exactly what is playing out with the large language models. While ChatGPT is getting all the attention, the actual interesting work is happening at the Frameworks layer that sits on top of the large language model Interfaces layer: the OpenAI, Anthropic, and PaLM APIs.
The all-too-common trough of disillusionment that many technological innovations encounter can be described as the period of time between the Capability layer becoming available and the Interfaces and Frameworks layers filling in to support the Applications layer.
For instance, if you want to make better guesses about the future of the most recent AI spring, pay attention to what happens with projects like LangChain, AutoGPT, and other tinkering adventures – they are the ones accumulating the recipes and practices that will form the foundation of the Frameworks layer. They will be the ones defining the shape of the Applications layer.
Here’s the advice I would give to any team developing a nascent technology:
Once the Capabilities layer exists, immediately focus on developing the Interfaces layer. For example, if you have a cool new way to connect devices wirelessly, offer an API for it.
Do make sure that your Interfaces layer encourages tinkering. Make the API as simple as possible, but still powerful enough to be interesting. Invest into capping the downside (misuse, abuse, etc.). For example, start with an invitation-only or rate-limited API.
Avoid the comforting idea that just playing with the Interfaces layer within your team or organization constitutes tinkering. Seek out a diverse group of tinkerers. Example: opt for a public preview program rather than an internal-only hackathon.
Prepare for the long slog of evolving the Interfaces layer. Consider maintaining the Interfaces layer as a permanent investment. Grow expertise on how to maintain the layer effectively.
Once the Interfaces layer usage starts growing, watch for the emergence of the Frameworks layer. Seed it with your own patterns and frameworks, but expect them not to take root. There will be other great tool or library ideas that you didn’t come up with. Give them all love.
Do invest in growing a healthy Frameworks layer. If possible, assume the role of the Frameworks layer facilitator and patron. Garden this layer and support those who are doing truly interesting things. Weed out grift and adversarial players. At the very least, be very familiar with the Frameworks landscape. As I mentioned before, this layer defines the shape of Applications to come.
Do build applications that utilize the technology, but only to learn more about the Frameworks layer. Use these insights to guide changes in Interfaces and Capabilities layer.
Be patient. The key to finding valuable opportunities is in being present when these opportunities come up – and being the most prepared to pursue these opportunities.
If you orient your work around these four layers, you might find that the rhythm of the pattern begins to work for you, rather than against you.
Now that I play a bit more with open source projects, more observations crystallize into framings, and more previous experiences start making sense. I guess that’s the benefit of having done this technology thing for a long time – I get to compost all of my learnings and share the yummy framings that grow on top of them.
One such framing is the distinction between two stances that projects have in regard to bad code committed into the repository: the fix-forward stance and the rollback stance.
“Bad code” in this scenario is usually the code that breaks something. It could be that the software we’re writing becomes non-functional. It could be as subtle as a single unit test begins to fail. Of course, we try to ensure that there are strong measures to prevent bad code from ever sneaking into the repository. However, no matter how much continuous integration infrastructure we surround ourselves with, bad code still occasionally makes it through.
When the project has a fix-forward stance, when the bad code is found, we keep moving forward, fixing the code with further commits.
In the rollback stance, we identify and immediately revert the offending commit, removing the breakage.
⏩ The fix-forward stance
The fix-forward stance tends to work well in smaller projects, where there is a high degree of trust and collaboration between the members of the project. The breakage is treated as a “fire”, and everyone just piles on to try and repair the code base.
One way to think of the fix-forward stance is that it places the responsibility of fixing the bad code on the collective shoulders of the project members.
One of my favorite memories from working on the WebKit project were the “hyatt landed” moments, when one of the founding members of the project would land a massive chunk of code that introduces a cool new feature or capability. This chunk usually broke a bunch of things, and members of the project would jump on putting out the fires, letting the new code finish cooking in the repository.
The obvious drawback of the fix-forward stance is that it can be rather randomizing. Fixing bad code and firefighting can be exhilarating for a few times, but grows increasingly frustrating, especially as the project grows in size and membership.
Another drawback of fixing forward is that it’s very common for more bad code to be introduced while fighting the fire, resulting in a katamari ball of bugs and a prolonged process of deconstructing this ball and weeding out all the bugs.
🔁 The rollback stance
This is where the rollback stance becomes more appealing. In this stance, the onus of responsibility for the breakage is on the individual contributor. If my code is deemed to be the culprit, it is simply ejected from the repository, and it’s on me to figure out the source of the brokenness.
In projects with the rollback stance, there is often a regular duty of “sheriffing” where an engineer or two are deputized to keep an eye on the build to spot effects of bad commits, hunt them down, and roll them back. The sheriff usually has the power to “close the tree”, where no new code is allowed to land until the problematic commit was reverted.
It is not fun to get a ping from a sheriff, letting me know that my patch was found to be the latest suspect in the crimes against the repository. There’s usually a brief investigation, with the author pleading for innocence, and a quick action of removing the commit from the tree.
The key advantage of the rollback stance is that it’s trustless in its nature, and so it scales rather well to large teams with diverse degrees of engagement. It doesn’t matter if I am a veteran who wrote most of the code in the project or someone who is making their first commit in hobby time – everyone is treated in the same way.
However, there are also several drawbacks. First, it could take a while for complicated changes to land. I’ve seen my colleagues orchestrate intricate multi-part maneuvers to ensure that all dependencies are properly adjusted and do not introduce breakages in the process.
There is also a somewhat unfortunate downside of the trustless environment: because it is on me to figure out the problem, it can be rather isolating. What could have been a brief firefighting swarm in a fix-forward project can turn into a long lonely slog of puzzling over the elusive bug. This tends to particularly affect less experienced and introverted engineers, who may spend weeks or even months trying to land a single patch, becoming more and more dejected with each rollback.
Similarly, it takes nuance and personal awareness to be an effective sheriff. A sheriff must constantly balance between quick action and proper diagnosis. Quite often, actually innocent code gets rolled out, while the problematic bits remain — or the sheriff loses large chunks of time while trying to diagnose the problem too deeply, and thus holding up the entire project. While working on Chromium, I’ve seen folks who are genuinely good at this job – and folks who I would rather not be sheriffing at all.
Because it is trustless, a rollback stance can easily lead to confrontational and zero-sum dynamics. Be very careful here and cultivate the spirit of collaboration and sense of community, lest we end up with a project where everyone is out for themselves.
📚 Lessons learned
Which stance should you pick for your next project? I would say it really depends on the culture you’d like to hold up as the ideal for the project.
If this is a small tight-knit group of folks who already work together well, the fix-forward stance is pretty effective. Think startups, skunkworks, or prototyping shops that want to stay small and nimble.
If you’d like your project to grow and accept many contributors, a rollback stance is likely the right candidate – as long as it is combined with strong community-building effort.
What about mixing the two? My intuition is that a combination of both stances can work within the same project. For example, some of the more stable, broader bits of the project could adopt the rollback stance, and the more experimental parts could be in a fix-forward stance. As long as there is a clean dependency separation between them, this setup might work.
One thing to avoid is inconsistent application of the stance. For example, if for our project, we decide that seasoned contributors could be allowed to use the fix-forward stance, and the newcomers would be treated with rollbacks, we’ll have a full mess on our hands. Be consistent and be clear about the stance of your project – and stick with it.
I’ve been thinking recently about how to design an open source project, and realized that there’s a really neat framing hiding in my memory. So I dug it out. If you are trying to make sense of the concepts of forking source code, see if this framing works for you.
It is fairly common that we have a chunk of someone else’s open source code that we would like to use. Or maybe we are trying to best prepare for someone else to use our open source code. In either case, we typically want to understand how this might happen.
The framing that I have here is a three-stage progression. It really ought to have a catchy name. The three stages are: dependency, soft fork, and hard fork. In my experience, a lot of open source code tends to go through this progression, sometimes more than once.
Depending on a particular situation, we might not be starting at the beginning of the sequence. As I will illustrate later, a project might not even move through this sequence linearly. This framing is an oversimplification for the sake of clarity. I hope you get the general gist, and then will be able to apply it flexibly.
🔗 Dependency stage
When we see a useful bit of source code, we start at the “dependency” stage. We want to consume this code, so we include it into our build process or import it directly into our project as-is. Using someone else’s code as a dependency has benefits and drawbacks.
The benefits of dependencies are that we don’t have to write or maintain this code. It serves as a layer of abstraction on top of which we build our thing, no longer needing to worry about the details hidden in this layer of abstraction.
The drawbacks come out of the failure of the assumptions made in the previous paragraph. Depending on the layer gaps this dependency contains or the sort of opinion it imposes, we might find that the code doesn’t quite do what we want.
At this point, we have two choices. The first choice is to continue treating this code as a dependency and try to fill in the gaps or shift the opinion by contributing back to the project from which this code originates. However, at this point, we are now participating in two projects: ours and the dependency’s. Depending on how different the projects’ organization and cultures are, we may start incurring an extra cost that we didn’t expect before: the cost of navigating across project boundaries.
If these costs start presenting an obstacle for us, the second choice starts looking mighty appealing. This second choice moves us to the next stage in our progression: the soft fork.
🍝 Soft fork stage
When soft-forking, we create a fork of the open source code, but commit to regularly pulling commits from the original. This is very common in situations where we ourselves do not have enough resources (expertise, bandwidth, etc.) and the original code is being actively improved. Why not get the best of both worlds? Get the latest improvements from the original while making our own improvements in our copy.
In practice, we end up underestimating the costs of maintaining the fork. Especially when the original project is moving quickly, the divergence of thinking across the two pools of people who are working on same-but-different-but-same code starts to rapidly unravel our plans of the soft fork harmony. We end up caught in the trap of having to accommodate both the thinking of our team and the team that’s working on the original code – and that is frankly the recipe for madness. Maintenance costs start growing non-linearly, when our assumptions that it will “just be a simple merge” begin exploding, the timebombs that they are.
Because of that, the “soft fork” stage is rarely a stable resting place in our progression. To abate the growing discontent, we are once again faced with two choices: go back to the “dependency” stage or proceed forward to the next stage in our little progression. Both are expensive, which makes the soft fork a nasty kind of trap.
Going back to the “dependency” stage means investing extra energy into upstreaming all of the accumulated code and insights. Many of them will be incompatible with what the original code maintainers think and like. Prepare for grueling debates and frustrations. Bring lots of patience and funding.
🔱 Hard fork stage
Moving forward to the “hard fork” stage means going our own way – and losing the benefit of the expertise and investment that made the soft fork so appealing in the first place. If we are a lean team that thought it would do a cool trick of drafting behind a larger team with our soft fork, this would be an impossible proposition.
Hard-forking is rarely beneficial in the short term. For a little while, we will be just learning how to run this thing by ourselves, and it will definitely feel like a dent in velocity. However, if we are persistent, a hard-forked project eventually regains its groove. Skill gaps are filled, duality of opinions is reduced, and the people around the project form unique culture and identity.
The key challenge of hard forks is that of utility. In the end, if the hard fork is not that different from the original, a natural question emerges: why do we need both? Depending on the kind of environment these projects inhabit, this question could be easily answered — or not.
📖 Story time
To give you an example of this progression, here’s an abbreviated (and likely embellished by yours truly) story of the relationship between Chromium and WebKit projects.
The Chromium project worked in secret for about two years, quickly going from WebKit being a dependency to a soft fork, with a semi-regular merge process. The shift from dependency to soft fork was pretty much necessary, given that the Chromium folks wanted to embed a different JavaScript engine than WebKit. This engine will end up being named “V8”.
In the last year or so prior to release, the team decided to temporarily shift to a hard fork stage. When I joined the team one month before public release, returning back to the soft fork stage was my first big project. Since I was thrilled to work on a browser project, I remember reporting happily that I was down to just 400 linker errors. When my colleagues, wide-eyed, turned to stare at me, I would add that last week it was over 3000.
Once the first merge was successful, my colleague Ojan strongly advocated for a daily merge. I couldn’t understand why this was so important back then, but this particular learning opportunity presented itself nearly immediately. There was a strongly super-linear relationship between the difficulty of the merge and the number of commits in it. If the merge contained just a handful of commits, it wasn’t that big of a deal. However, if the number exceeded a few dozen, we would be in deep trouble – making sense of the changes and how they intersected with the changes we’ve made spiraled out of control.
Simultaneously, we committed to “unforking” – that is, to moving all the way back to the “dependency” stage, where Chromium consumed WebKit as a pure dependency. This was a wild time. We were doing three things at once: performing continuous merge with the tip-of-tree WebKit, shuttling our Chromium diffs over to WebKit, and building a browser. I still think of those times fondly. It was such a fun puzzle.
Over a year later – and that tells you about the sheer amount of work that was necessary to make all this happen – we were unforked. We moved all the way back to the first stage of the progression. At that point, the WebKit project’s code was just one of the dependencies of Chromium. We focused on making more and more contributions upstream, and the team that was working on WebKit directly grew.
Ultimately, as you may know, we forked again, creating Blink. This particular move was a hard fork, skipping a stage in the sequence. This wasn’t an easy decision, but having explored and understood the soft fork, we knew that it wasn’t what we’re looking for.
✨ What I learned
With this framing, I accumulated a few insights. Here they are. Your mileage may vary.
When consuming open source projects:
Be aware that soft forks are always a lot more expensive than they look.
There will be many different ideas that make soft forks look appealing, including neat techniques of carrying patches and clever tooling to seamlessly apply them. These don’t reduce the costs. They just hide them.
When stuck with soft-forking, put all your energy into reducing the delay between merges. The beer game dynamic will show up otherwise.
In our own open source project:
Work hard to reduce the need to be soft-forked. Invest extra time to make configuration more flexible. Accommodate diverse needs. We are better off having these folks work in the main tree rather than wasting energy on a soft work.
Culture of inviting contribution and respect of insights from others is paramount: when signing up to run an open source project, we accept the future where the project will morph and change from our original intention. Lean into that, rather than trying to prevent it.
Riffing on the idea of layer gaps, we can surmise that pretty much every layer we ever get to write code for has gaps. If that’s the case, then anticipating layer gaps in our future can lead to different ways to build teams.
A key insight from the previous essay is that when we work with a layer with gaps, we need to understand both this layer and the layer underneath it. For if we ever fall into the gap, we could use that knowledge of the lower layer to orient and continue toward our intended destination.
Which means that when we hire people to work in a certain stack, we are much better off hiring at least one person who has experience with the stack’s lower layer. These are the people who will lead the team out of the layer gaps. To give our full stack engineers the ability to overcome these gaps, we need at least one deep stack engineer.
A simple rule of thumb: for every part of the stack, hire at least one person who has experience working at the layer below.
For example, if we’re planning to develop our product on top of a Web framework, we must look for someone who deeply understands this framework to join the team. Ideally, this person is a current or former active participant in the framework project.
Approaching this from a slightly different angle and applying the cost of opinion lens, this person will act as the opinion cost estimator for the team. Because they understand the actual intention of the framework, they can help our team minimize the difference of intentions between what we’re engineering in our layer and the intention of the underlying framework. As my good friend Matt wisely said many moons ago, it would help our team “use the platform” rather than waste energy while trying to work around it. Or worse yet, reinvent it.
Note that the experience at the lower layer does not necessarily translate to the experience at the higher layer. I could be a seasoned Web platform engineer, with thousands of lines of rendering engine C++ code under my belt – yet have very little understanding of how Web applications are built.
What we’re looking for in a deep stack engineer is the actual depth: the capacity to span multiple layers, and go up and down these layers with confident ease.
The larger the count of layers they span, the more rare these folks are. It takes a lot of curiosity and experience to get to the level of expert comfort across multiple layers of developer surfaces. Usually, folks tend to nest within one layer and build their careers there. So next time we come across a candidate whose experience spans across two or more, we are apt to pay attention: this might be someone who significantly improves the odds of success in our engineering adventures.