This post is more technical and more rambling than my usual repertoire. It’s a deep dive into where my mind is today, and it’s mostly about technical design. Think of it as a sample of interesting problems that I am puzzling over these days.
Let’s start with graphs. In the past, I’ve mentioned this interesting tension between graphs and trees: how our human tendency to organize things into tree-like structures (hierarchies and other container models) is at odds with the fluid, interconnected nature of the world around us. I framed it as: “every graph wants to become a tree, and still secretly wants to remain a graph”, and described in the context of developer frameworks.

So naturally, when presented with an opportunity to write a developer library, I decided to use the graph structure as its core. The result is Breadboard. It’s still early on. I like to say that we currently have a toddler, and there’s much left to do to get the library to adulthood. However, it seems useful to start sharing what I’ve learned so far and design decisions I landed on.
🐱Whyyyy
If you even occasionally scan these chronicles of my learnings, you will undoubtedly know that I am fascinated by the potential of applying large language models (LLMs) as a technology and the kinds of new interesting spaces they could open.
As a result, I invested quite a bit of time tinkering with the models, trying to make them jump through various hoops and do things – just to get a sense of what it is that they are truly capable of. Judging from the endless updates I hear from my friends and colleagues, so is everyone else.
New interesting patterns of applying LLMs seem to arise almost daily – and that’s pretty exciting. What was less exciting for me was the distinct lack of tools that help us discover these patterns. Most of the frameworks that are rising to relative prominence appear to focus on capturing the newly discovered patterns and making them more accessible. This is great! But what about a framework that facilitates tinkering with LLMs to find new patterns?
I started Breadboard with two objectives in mind:
- Make creating new generative AI patterns accessible and fun
- Enable easy sharing, remixing, composition, and reuse of these patterns.
My hope is that Breadboard helps accelerate the pace with which new interesting and useful patterns for applying generative AI are found. Because honestly, it feels like we have barely scratched the surface. It would be super-sad if the current local maxima of chatbots would be as far as we get with this cycle of AI innovation.
🍞The metaphor
The first thing I wanted to get right was the mental model with which a developer might approach the library.
Graphs are typically hard to describe. I am in awe with whomever came up with the term “Web” to describe the entire tangle of the hyperlinked documents. Kudos.
As you may remember, I am also very interested in the role makers play in the generative AI space. That’s how breadboards came to mind: the solderless construction bases for prototyping electronic circuits. Breadboards are a perfect maker’s tool. They are easy to put together and easy to take apart, to change the layout and tinker with various parts.
Lucky for me, breadboards are also graphs: the electronic circuits they carry are directed graphs, where each electronic component is a node in the graph and the jump wires that connect them are edges. By placing different nodes on the board and wiring them in various ways, we get different kinds of prototypes.
This is exactly what I was looking for: a one-word name for the library that comes with the mental model for what it does. As an additional benefit, “breadboard” selects for makers: if you know and love breadboards (or even just the idea of breadboards), you will likely look forward to playing with this library.
🧩 The composition system
Another piece of the puzzle was composition. Over the last decade, I ended up studying composition and designing composable systems quite extensively. In Breadboard, I wanted to lay down a sound foundation for composition.
There are three different ways to compose things in Breadboard: 🧩 nodes, 🍱 kits, and 🎛️ boards.

🧩 Nodes are the most obvious unit of composition: we can place nodes on a breadboard and wire them together. At this layer of composition, makers compose nodes to make our prototypes. Once they have a neat prototype, makers can share the board that contains the prototype. A shared board is something that anyone can pull down from a URL and start playing with it. They can clone it, tweak it, and share it again.
To get the node composition right, we need a set of nodes that allow us to build something useful and interesting. While still at an early stage, it is my intent to arrive at a starter kit of sorts: a relatively small set of general-purpose nodes that enable making all kinds of cool things.
🍱 We don’t have to stop with just one kit. Kits are another unit of composition. Makers are able to create and group interesting nodes into kits – and publish them to share with others. For instance, a project or a company might want to wrap their interesting services as nodes and publish them as a kit, allowing any maker to grab those nodes and start using them in their boards.
A maker can also just build a kit for themselves, and use it in their own prototyping only. While kits do not need to be published, boards that use unpublished kits can’t be shared with others – or at least shared in any useful way.
🎛️ Boards themselves are also units of composition. Makers can include boards of others into their board, turning an included board into a sort of virtual node. The board inclusion feature is similar to a hyperlink: just like on the Web, including a board simply links from one board to another, rather than subsuming it. Such loose coupling unlocks the full potential for interdependent collaboration, and I fully expect the common dependency management practices to be applicable.
In addition to inclusion, boards can have slots. Slots are another way to add modularity to boards. When I build a board, I can leave it incomplete by specifying one or more places – “slots” – where someone else can include their boards. This is a useful trick that software developers call “dependency injection”. For instance, if I developed a generic pattern to invoke various tools with generative AI, I can leave a slot for these tools. When other makers reuse my board, they can insert their own sets of tools into this slot without having to modify my board.
🤖 The traversal machine
It took me a little bit of time to settle on what is a “node” in Breadboard and how these nodes get traversed in the graph. I ended up going with the actor model-inspired design, leaving lots of room to explore concurrency and distributed processing in the future. For the moment however, I am primarily guided by the motivation to make Breadboard graphs easy to understand.
One capability I wanted to enable was building graphs that have cycles within them. Pretty much anything interesting contains feedback loops, and so Breadboard supports directed graphs with cycles out of the box. Calculating topography of such graphs is an NP-complete problem, but lucky for us, traversing them is fairly trivial. After all, most computer programs are directed graphs with cycles.
At the core of the traversal machine is this concept: a well-behaving node is a pure function. More precisely, as close to a pure function as we can get. Since makers can create their own nodes, Breadboard can’t guarantee any of that, but I’d like to encourage it.
Since pure functions don’t contain state, state needs to be managed outside of the function. Breadboard relies on wires as the method to manage state. Wires are the way both data and control flow.
This sets up the basics of the traversal logic:
- Every node has inputs and outputs. The inputs are the wires running into the node, and outputs are wires running out. A node consumes inputs and provides outputs.
- The node – or technically the function that the node represents – is only run when all inputs have been provided to it by the nodes that ran before this node. Put differently, a node will not run if some of its inputs weren’t provided.
- Graph traversal starts with running nodes that don’t have any inputs wired into them.
That’s about it.
To geek out on this a bit more, I went with a mailbox-like setup where wires are effectively one-time variables that store data. The data in this variable is written by a node output and read by a node input. A super-cool effect of such a setup is that the state of the graph is captured entirely in the wires, which means that Breadboard can pause and resume traversal of the graph by saving what’s currently stored in the wires.
🚧 What is next
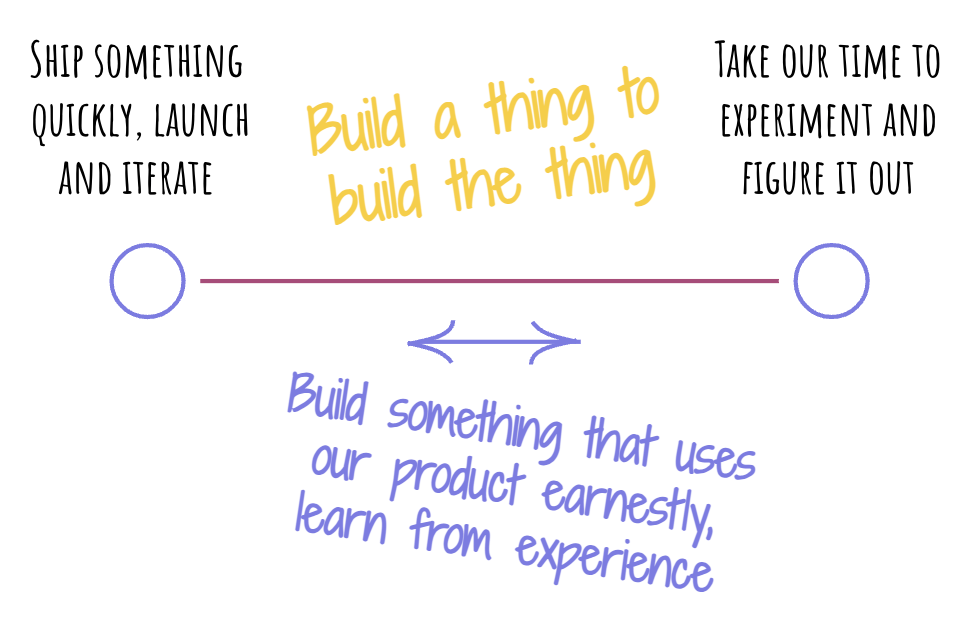
Looking ahead, I am quite optimistic about Breadboard. We already have a small seedling of a team developing. In the next few weeks, I’ll keep making interesting patterns with it to keep informing the development of the library. Build a thing to build the thing, right?
Once the fundamentals settle a bit, we can start thinking about graduating Breadboard into an early adulthood, releasing the v1. Hopefully, at this point, we will have enough onramp for you and other makers to start actively using it in your prototyping adventures.
If you feel excited about this idea and don’t want to wait until then, please check out the list of open issues on Github and join the conversation. Be prepared to eat unbaked cookies and occasionally find bits of construction debris in them – and help make Breadboard better.